
иә«зӮәзӣ®еүҚжңҖеј·зҡ„AIеҠ йҖҹйҒӢз®—е–®е…ғпјҢBlackwell GPUдёҚдҪҶе…·жңүеј·жӮҚзҡ„ж•ҲиғҪпјҢйӮ„еҸҜйҖҸйҒҺдёІжҺҘеӨҡзө„GPUж–№ејҸж§Ӣе»әгҖҢи¶…еӨ§еһӢGPUгҖҚпјҢеё¶дҫҶжӣҙй«ҳзҡ„зёҪй«”ж•ҲиғҪиҲҮеҗһеҗҗйҮҸгҖӮ
дёҚеҗҢж•ЈзҶұиҲҮд»Ӣйқўзө„ж…Ӣ
NVIDIAжҺЁеҮәдәҶеӨҡзЁ®Blackwell GPUзө„ж…ӢпјҢеҢ…еҗ«ж•ҙеҗҲ8зө„GPUзҡ„HGXеҪўејҸи¶…зҙҡйӣ»и…ҰпјҢд»ҘеҸҠж•ҙеҗҲ2зө„GPUжҗӯй…Қ1зө„Grace CPUзҡ„GB200йҒӢз®—зҜҖй»һпјҢиҖҢе®ғеҖ‘еҸҲеҸҜд»ҘеҪјжӯӨдёІйҖЈжҲҗзӮәжӣҙеӨ§еһӢзҡ„йҒӢз®—еҸўйӣҶгҖӮ
- 延伸й–ұи®Җпјҡ
- GTC 24пјҡBlackwellжһ¶ж§Ӣи©іи§ЈпјҲдёҠпјүпјҢе…Ёж–°жһ¶ж§Ӣеё¶дҫҶ5еҖҚж•ҲиғҪиЎЁзҸҫ
- GTC 24пјҡBlackwellжһ¶ж§Ӣи©іи§ЈпјҲдёӢпјүпјҢзңӢжҮӮB100гҖҒB200гҖҒGB200гҖҒGB200 NVL72жҲҗе“Ўзҡ„зіҫзөҗз“ңи‘ӣпјҲжң¬ж–Үпјү
- GTC 2024жҳҘеӯЈе ҙзі»еҲ—е ұе°Һзӣ®йҢ„
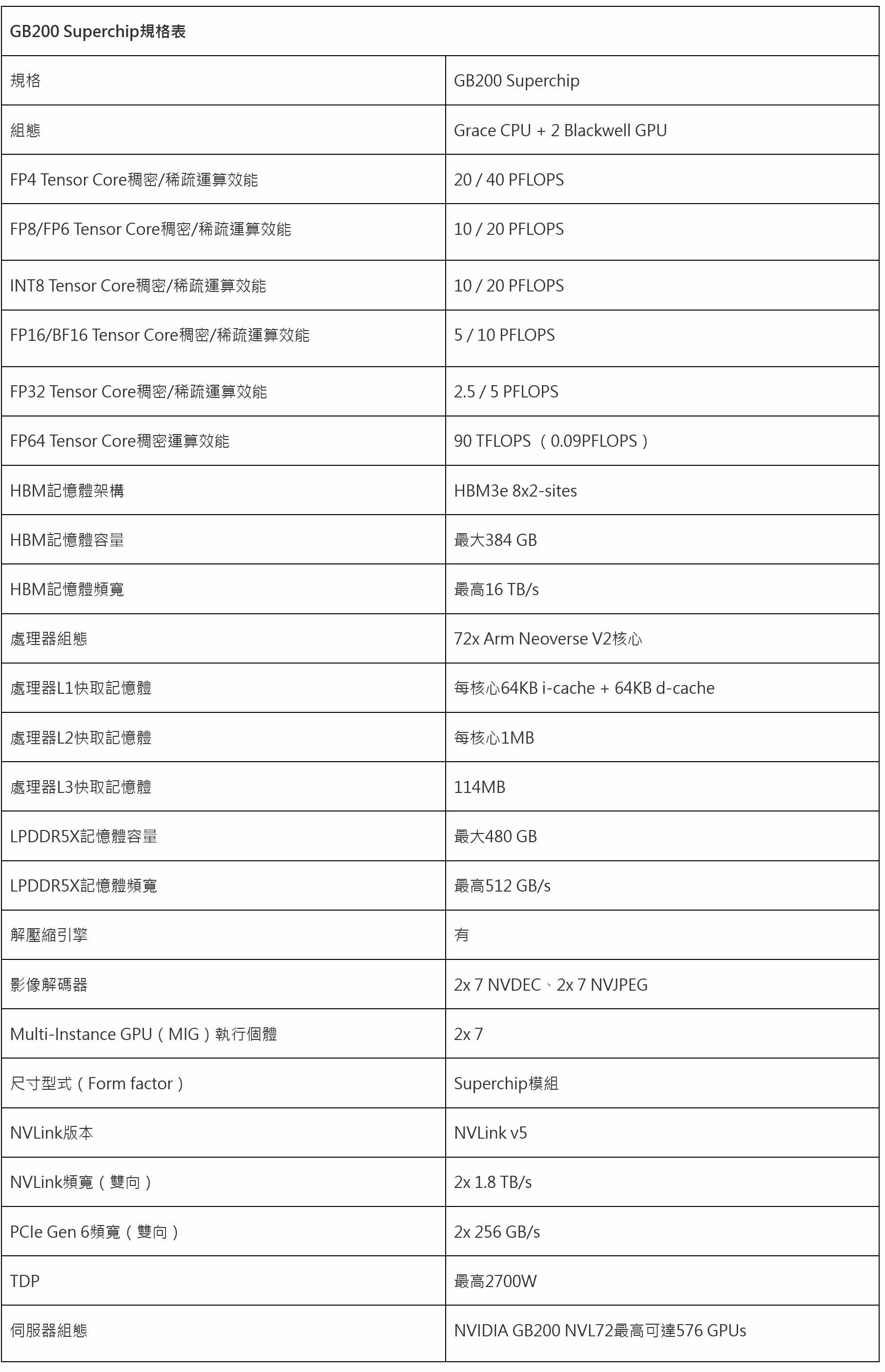
NVIDIAеңЁGTCеӨ§жңғдёҠдё»иҰҒжҺЁе»Јзҡ„еһӢиҷҹзӮәж•ҙеҗҲ2зө„Blackwell GPUиҲҮ1зө„Grace CPUзҡ„GB200 SuperchipпјҢNVIDIAжҺЁеҮәзҡ„GB200 SuperchipйҒӢз®—зҜҖй»һпјҲCompute NodeпјүеүҮжҳҜе°Ү2зө„GB200 Superchipе®үзҪ®ж–ј1Uй«ҳеәҰзҡ„дјәжңҚеҷЁпјҢдёҰжҺЎз”Ёж°ҙеҶ·ж•ЈзҶұж–№жЎҲпјҢиғҪи®“е–®зө„GB200 Superchipзҡ„TDPйҒ”еҲ°2700WпјҢе®Ңе…Ёи§Јж”ҫж•ҲиғҪиЎЁзҸҫгҖӮ
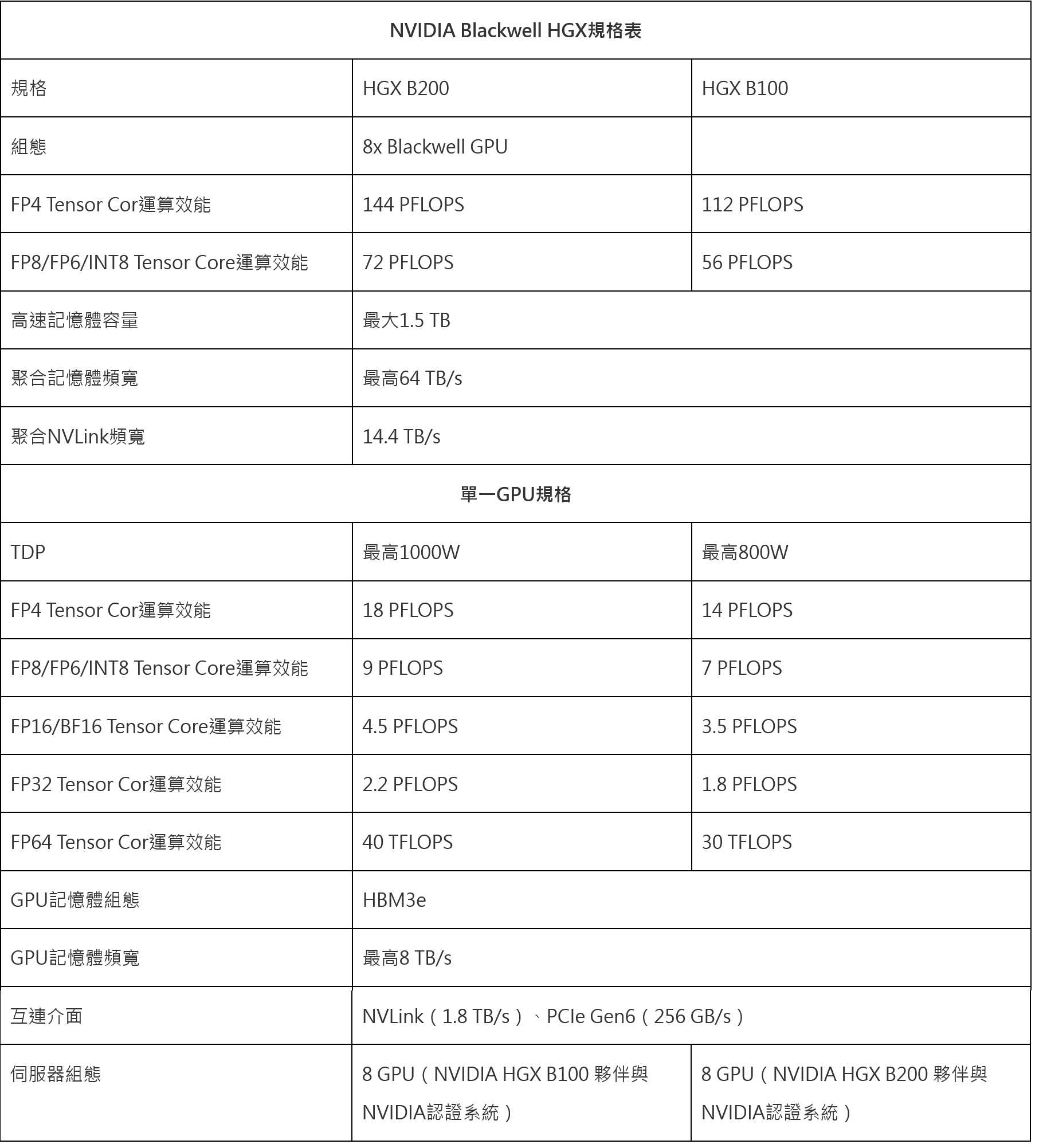
жӯӨеӨ–NVIDIAд№ҹжңғжҺЁеҮәжҺЎз”ЁSXGд»Ӣйқўзҡ„B200иҲҮB100зӯүGPUпјҢдё”йғҪиғҪеӨ д»Ҙ8зө„GPUзө„жҲҗHGX B200жҲ–HGX B100дјәжңҚеҷЁпјҢ2иҖ…дё»иҰҒзҡ„е·®з•°еңЁж–јB200зҡ„TDPжңҖй«ҳеҸҜйҒ”1000WпјҢиҖҢB100еғ…зӮә800WгҖӮ
NVIDIAи¶…еӨ§иҰҸжЁЎиҲҮй«ҳж•ҲиғҪйҒӢз®—еүҜзёҪиЈҒжҡЁзёҪ經зҗҶIan Buckд№ҹеңЁеӘ’й«”иЁӘи«ҮдёӯиЈңе……иӘӘжҳҺпјҢиӢҘе°ҮB200е®үзҪ®ж–јдјәжңҚеҷЁдёҰжҗӯй…Қж°ҙеҶ·ж•ЈзҶұж–№жЎҲпјҢеүҮеҸҜе°ҮTDPдёҠиӘҝиҮі1200WпјҢйҖІдёҖжӯҘжҸҗй«ҳйҒӢз®—ж•ҲиғҪгҖӮ
еҸҰдёҖж–№йқўпјҢеңЁж•ЈзҶұиҲҮдҫӣйӣ»иЁұеҸҜзҡ„зҜ„еңҚдёӢпјҢB200иҲҮB100 GPUиғҪеӨ зӣҙжҺҘиҲҮзҸҫжңүH100 HGXжҲ–зӣёе®№дјәжңҚеҷЁйҖІиЎҢGPUжӣҝжҸӣпјҲDrop-in ReplaceпјүпјҢжҸҗдҫӣжӣҙеӨ§зҡ„еҚҮзҙҡеҪҲжҖ§дёҰзҜҖзңҒеҚҮзҙҡиІ»з”ЁгҖӮ
пјҲиӢҘдёӢж–№иЎЁж јз„Ўжі•е®Ңж•ҙйЎҜзӨәпјҢи«Ӣй»һйҒёжҲ‘зңӢең–зүҮзүҲпјү
{kind=link}
| GB200 SuperchipиҰҸж јиЎЁ | |
| иҰҸж ј | GB200 Superchip |
| зө„ж…Ӣ | Grace CPU + 2 Blackwell GPU |
| FP4 Tensor CoreзЁ еҜҶ/зЁҖз–ҸйҒӢз®—ж•ҲиғҪ | 20 / 40 PFLOPS |
| FP8/FP6 Tensor CoreзЁ еҜҶ/зЁҖз–ҸйҒӢз®—ж•ҲиғҪ | 10 / 20 PFLOPS |
| INT8 Tensor CoreзЁ еҜҶ/зЁҖз–ҸйҒӢз®—ж•ҲиғҪ | 10 / 20 PFLOPS |
| FP16/BF16 Tensor CoreзЁ еҜҶ/зЁҖз–ҸйҒӢз®—ж•ҲиғҪ | 5 / 10 PFLOPS |
| FP32 Tensor CoreзЁ еҜҶ/зЁҖз–ҸйҒӢз®—ж•ҲиғҪ | 2.5 / 5 PFLOPS |
| FP64 Tensor CoreзЁ еҜҶйҒӢз®—ж•ҲиғҪ | 90 TFLOPS пјҲ0.09PFLOPSпјү |
| HBMиЁҳжҶ¶й«”жһ¶ж§Ӣ | HBM3e 8x2-sites |
| HBMиЁҳжҶ¶й«”е®№йҮҸ | жңҖеӨ§384 GB |
| HBMиЁҳжҶ¶й«”й »еҜ¬ | жңҖй«ҳ16 TB/s |
| иҷ•зҗҶеҷЁзө„ж…Ӣ | 72x Arm Neoverse V2ж ёеҝғ |
| иҷ•зҗҶеҷЁL1еҝ«еҸ–иЁҳжҶ¶й«” | жҜҸж ёеҝғ64KB i-cache + 64KB d-cache |
| иҷ•зҗҶеҷЁL2еҝ«еҸ–иЁҳжҶ¶й«” | жҜҸж ёеҝғ1MB |
| иҷ•зҗҶеҷЁL3еҝ«еҸ–иЁҳжҶ¶й«” | 114MB |
| LPDDR5XиЁҳжҶ¶й«”е®№йҮҸ | жңҖеӨ§480 GB |
| LPDDR5XиЁҳжҶ¶й«”й »еҜ¬ | жңҖй«ҳ512 GB/s |
| и§ЈеЈ“зё®еј•ж“Һ | жңү |
| еҪұеғҸи§ЈзўјеҷЁ | 2x 7 NVDECгҖҒ2x 7 NVJPEG |
| Multi-Instance GPUпјҲMIGпјүеҹ·иЎҢеҖӢй«” | 2x 7 |
| е°әеҜёеһӢејҸпјҲForm factorпјү | SuperchipжЁЎзө„ |
| NVLinkзүҲжң¬ | NVLink v5 |
| NVLinkй »еҜ¬пјҲйӣҷеҗ‘пјү | 2x 1.8 TB/s |
| PCIe Gen 6й »еҜ¬пјҲйӣҷеҗ‘пјү | 2x 256 GB/s |
| TDP | жңҖй«ҳ2700W |
| дјәжңҚеҷЁзө„ж…Ӣ | NVIDIA GB200 NVL72жңҖй«ҳеҸҜйҒ”576 GPUs |
В пјҲиӢҘдёӢж–№иЎЁж јз„Ўжі•е®Ңж•ҙйЎҜзӨәпјҢи«Ӣй»һйҒёжҲ‘зңӢең–зүҮзүҲпјү
{kind=link}
| NVIDIA Blackwell HGXиҰҸж јиЎЁ | ||
| иҰҸж ј | HGX B200 | HGX B100 |
| зө„ж…Ӣ | 8x Blackwell GPU | В |
| FP4 Tensor CorйҒӢз®—ж•ҲиғҪ | 144 PFLOPS | 112 PFLOPS |
| FP8/FP6/INT8 Tensor CoreйҒӢз®—ж•ҲиғҪ | 72 PFLOPS | 56 PFLOPS |
| й«ҳйҖҹиЁҳжҶ¶й«”е®№йҮҸ | жңҖеӨ§1.5 TB | |
| иҒҡеҗҲиЁҳжҶ¶й«”й »еҜ¬ | жңҖй«ҳ64 TB/s | |
| иҒҡеҗҲNVLinkй »еҜ¬ | 14.4 TB/s | |
| е–®дёҖGPUиҰҸж ј | ||
| TDP | жңҖй«ҳ1000W | жңҖй«ҳ800W |
| FP4 Tensor CorйҒӢз®—ж•ҲиғҪ | 18 PFLOPS | 14 PFLOPS |
| FP8/FP6/INT8 Tensor CoreйҒӢз®—ж•ҲиғҪ | 9 PFLOPS | 7 PFLOPS |
| FP16/BF16 Tensor CoreйҒӢз®—ж•ҲиғҪ | 4.5 PFLOPS | 3.5 PFLOPS |
| FP32 Tensor CorйҒӢз®—ж•ҲиғҪ | 2.2 PFLOPS | 1.8 PFLOPS |
| FP64 Tensor CorйҒӢз®—ж•ҲиғҪ | 40 TFLOPS | 30 TFLOPS |
| GPUиЁҳжҶ¶й«”зө„ж…Ӣ | HBM3e | |
| GPUиЁҳжҶ¶й«”й »еҜ¬ | жңҖй«ҳ8 TB/s | |
| дә’йҖЈд»Ӣйқў | NVLinkпјҲ1.8 TB/sпјүгҖҒPCIe Gen6пјҲ256 GB/sпјү | |
| дјәжңҚеҷЁзө„ж…Ӣ | 8 GPUпјҲNVIDIA HGX B100 еӨҘдјҙиҲҮ NVIDIAиӘҚиӯүзі»зөұпјү |
8 GPUпјҲNVIDIA HGX B200 еӨҘдјҙиҲҮ NVIDIAиӘҚиӯүзі»зөұпјү |
 в–І Blackwell GPUзҡ„еҜҰй«”ең–зүҮпјҢжӣҙеӨҡи©ізҙ°д»Ӣзҙ№еҸҜзңӢзӯҶиҖ…зҡ„еүҚзҜҮе ұе°ҺгҖӮ
в–І Blackwell GPUзҡ„еҜҰй«”ең–зүҮпјҢжӣҙеӨҡи©ізҙ°д»Ӣзҙ№еҸҜзңӢзӯҶиҖ…зҡ„еүҚзҜҮе ұе°ҺгҖӮ
 в–І GB200 Superchipж•ҙеҗҲ2зө„Blackwell GPUиҲҮ1зө„Grace CPUгҖӮ
в–І GB200 Superchipж•ҙеҗҲ2зө„Blackwell GPUиҲҮ1зө„Grace CPUгҖӮ
 в–І GB200 Superchipзҡ„еҜҰй«”ең–зүҮпјҢдёҠж–№зӮә2зө„Blackwell GPUпјҢдёӯеӨ®еүҮзӮәGrace CPUиҲҮLPDDR5xиЁҳжҶ¶й«”гҖӮ
в–І GB200 Superchipзҡ„еҜҰй«”ең–зүҮпјҢдёҠж–№зӮә2зө„Blackwell GPUпјҢдёӯеӨ®еүҮзӮәGrace CPUиҲҮLPDDR5xиЁҳжҶ¶й«”гҖӮ
 в–І жҜҸзө„Blackwell GPUе…§е»әе®№йҮҸзӮә384 GBзҡ„HBM3eй«ҳй »еҜ¬иЁҳжҶ¶й«”гҖӮ
в–І жҜҸзө„Blackwell GPUе…§е»әе®№йҮҸзӮә384 GBзҡ„HBM3eй«ҳй »еҜ¬иЁҳжҶ¶й«”гҖӮ
 в–І Grace CPUеүҮеңЁеӨ–йғЁй…ҚзҪ®жңҖеӨ§480 GB LPDDR5XиЁҳжҶ¶й«”гҖӮ
в–І Grace CPUеүҮеңЁеӨ–йғЁй…ҚзҪ®жңҖеӨ§480 GB LPDDR5XиЁҳжҶ¶й«”гҖӮ
 в–І GB200 SuperchipйҒӢз®—зҜҖй»һж•ҙеҗҲ2зө„GB200 SuperchipпјҢжҗӯй…Қж°ҙеҶ·ж•ЈзҶұж–№жЎҲпјҢе®үзҪ®ж–ј1Uй«ҳеәҰзҡ„дјәжңҚеҷЁгҖӮпјҲе·Ұж–№зӮәеҺ»йҷӨж°ҙеҶ·й ӯзҡ„жғ…жіҒпјү
в–І GB200 SuperchipйҒӢз®—зҜҖй»һж•ҙеҗҲ2зө„GB200 SuperchipпјҢжҗӯй…Қж°ҙеҶ·ж•ЈзҶұж–№жЎҲпјҢе®үзҪ®ж–ј1Uй«ҳеәҰзҡ„дјәжңҚеҷЁгҖӮпјҲе·Ұж–№зӮәеҺ»йҷӨж°ҙеҶ·й ӯзҡ„жғ…жіҒпјү
 в–І жӯӨеӨ–е®ўжҲ¶д№ҹеҸҜд»ҘйҒёеүҮж•ҙеҗҲ8зө„SXGд»ӢйқўBlackwell GPUзҡ„HGX B200жҲ–HGX B100дјәжңҚеҷЁгҖӮ
в–І жӯӨеӨ–е®ўжҲ¶д№ҹеҸҜд»ҘйҒёеүҮж•ҙеҗҲ8зө„SXGд»ӢйқўBlackwell GPUзҡ„HGX B200жҲ–HGX B100дјәжңҚеҷЁгҖӮ
Blackwell GPUзҡ„еҸҰдёҖеӨ§еүөж–°еҠҹиғҪпјҢе°ұжҳҜиғҪеӨ йҖҸйҒҺNVLinkдёІиҒҜжңҖеӨҡ576зө„Blackwell GPUпјҢи®“ж•ҙеҖӢеҸўйӣҶзҢ¶еҰӮзө„жҲҗе–®дёҖи¶…еӨ§GPUпјҢйҒ”еҲ°ж“ҙеӨ§йҒӢз®—ж•ҲиғҪгҖҒе…ұдә«иЁҳжҶ¶й«”гҖҒеҹ·иЎҢиҰҸжЁЎжӣҙеӨ§жЁЎеһӢзҡ„иғҪеҠӣгҖӮ
иҖҢNVIDIAд№ҹжҺЁеҮәдәҶGB200 NVL72дјәжңҚеҷЁпјҢе®ғзҡ„ж©ҹж«ғпјҲRackпјүе…·жңү18зө„GB200 SuperchipйҒӢз®—зҜҖй»һд»ҘеҸҠ9зө„NVLinkдәӨжҸӣеҷЁпјҲжҜҸзө„дәӨжҸӣеҷЁе…·жңү2зө„NVLinkдәӨжҸӣеҷЁжҷ¶зүҮжүҖпјүпјҢиғҪеңЁз”ұ72зө„GPUзө„жҲҗзҡ„NVL72з¶ІеҹҹеҸўйӣҶдёӯпјҢд»Ҙ130 TB/sзҡ„й »еҜ¬дәӨжҸӣиіҮж–ҷгҖӮиҖҢи·ЁеӨҡеҸ°ж©ҹж«ғзҡ„GPUиіҮж–ҷеүҮжңғйҖҸйҒҺInfiniBandз¶Іи·ҜгҖӮ
зӣёе°Қж–јBlackwell GPUжҷ¶зүҮе…§йғЁзҡ„2зө„иЈёжҷ¶йҖҸйҒҺй »еҜ¬й«ҳйҒ”10 TB/sзҡ„NV-HBIпјҲNVIDIA High-Bandwidth Interfaceпјүжҷ¶зүҮе°Қжҷ¶зүҮдә’йҖЈпјҲChip-to-Chip InterconnectionпјүзӣёйҖЈпјҢеӨҡйЎҶGPUд№Ӣй–“еүҮжҳҜйҖҸйҒҺ第5д»ЈNVLinkзӣёйҖЈгҖӮе®ғжҺЎз”Ё18йҖҡйҒ“пјҲLinkпјүзҡ„й«ҳйҖҹе·®еҲҶиЁҠиҷҹе°ҚпјҲHigh-Speed Differential PairпјүпјҢиғҪеӨ жҸҗдҫӣзёҪе…ұй«ҳйҒ”1.8 TB/sзҡ„йӣҷеҗ‘й »еҜ¬пјҲеҚіе–®еҗ‘зӮә900 GB/sпјүпјҢжңҖй«ҳиғҪж”ҜжҸҙ576зө„GPUзӣёйҖЈпјҢйҒ й«ҳж–јеүҚд»Јзҡ„256зө„GPUгҖӮ
第5д»ЈNVLinkзҡ„й »йҒ йҒ й«ҳеҮәPCIe Gen 5x16зҡ„14еҖҚпјҢе…¶1е°ҸжҷӮзҡ„йӣҷеҗ‘еӮіијёйҮҸзёҪеҗҲзҙ„зӮә6.32 PBпјҢеӨ§зҙ„зӯүеҗҢж–ј18е№ҙ4Kйӣ»еҪұдёІжөҒзҡ„иіҮж–ҷйҮҸпјҢжҲ–жҳҜ11зө„Blackwell GPUд№Ӣй–“зҡ„еӮіж•ёйҮҸзёҪеҗҲе°ұиҲҮж•ҙеҖӢз¶Ійҡӣз¶Іи·Ҝзӣёз•¶пјҢе°Қж–јеҹ·иЎҢеӨ§еһӢAIжЁЎеһӢзҡ„ж•ҲиғҪиЎЁзҸҫжү®жј”йҮҚиҰҒи§’иүІгҖӮ
пјҲиӢҘдёӢж–№иЎЁж јз„Ўжі•е®Ңж•ҙйЎҜзӨәпјҢи«Ӣй»һйҒёжҲ‘зңӢең–зүҮзүҲпјү
{kind=link}
| NVIDIA GB200 NVL72иҰҸж јиЎЁ | |
| иҰҸж ј | NVIDIA GB200 NVL72 |
| зө„ж…Ӣ | 36x GB200 Superchip |
| FP4 Tensor CoreзЁ еҜҶ/зЁҖз–ҸйҒӢз®—ж•ҲиғҪ | 720 / 1440 PFLOPS |
| FP8/FP6 Tensor CoreзЁ еҜҶ/зЁҖз–ҸйҒӢз®—ж•ҲиғҪ | 360 / 720 PFLOPS |
| INT8 Tensor CoreзЁ еҜҶ/зЁҖз–ҸйҒӢз®—ж•ҲиғҪ | 360 / 720 PFLOPS |
| HBMиЁҳжҶ¶й«”жһ¶ж§Ӣ | HBM3e |
| HBMиЁҳжҶ¶й«”е®№йҮҸ | жңҖеӨ§13.5 TB |
| HBMиЁҳжҶ¶й«”й »еҜ¬ | жңҖй«ҳ576 TB/s |
| иҷ•зҗҶеҷЁзө„ж…Ӣ | 2592x Arm Neoverse V2ж ёеҝғ |
| й«ҳйҖҹиЁҳжҶ¶й«”е®№йҮҸ | жңҖеӨ§30 TB |
| NVLinkдәӨжҸӣеҷЁ | 7x |
| NVLinkй »еҜ¬пјҲйӣҷеҗ‘пјү | 130 TB/s |
 в–І NVLinkдәӨжҸӣеҷЁжҷ¶зүҮиғҪеӨ дёІиҒҜжңҖеӨҡ576зө„Blackwell GPUзө„жҲҗе–®дёҖи¶…еӨ§GPUпјҢйҒ”еҲ°ж“ҙеӨ§йҒӢз®—ж•ҲиғҪгҖҒе…ұдә«иЁҳжҶ¶й«”гҖҒеҹ·иЎҢиҰҸжЁЎжӣҙеӨ§жЁЎеһӢзҡ„иғҪеҠӣгҖӮ
в–І NVLinkдәӨжҸӣеҷЁжҷ¶зүҮиғҪеӨ дёІиҒҜжңҖеӨҡ576зө„Blackwell GPUзө„жҲҗе–®дёҖи¶…еӨ§GPUпјҢйҒ”еҲ°ж“ҙеӨ§йҒӢз®—ж•ҲиғҪгҖҒе…ұдә«иЁҳжҶ¶й«”гҖҒеҹ·иЎҢиҰҸжЁЎжӣҙеӨ§жЁЎеһӢзҡ„иғҪеҠӣгҖӮ
 в–І NVLinkдәӨжҸӣеҷЁз”ұ2зө„NVLinkдәӨжҸӣеҷЁжҷ¶зүҮж§ӢжҲҗпјҢдёҰжҸҗдҫӣ144зө„NVLinkз«ҜеӯҗпјҢз„Ўйҳ»еЎһдәӨжҸӣеҠүйҮҸзӯ”14.4 TB/sпјҢзӮәGB200 NVL72зі»зөұжҸҗдҫӣй«ҳй »еҜ¬е’ҢдҪҺ延йҒІиіҮж–ҷдәӨжҸӣиғҪеҠӣгҖӮ
в–І NVLinkдәӨжҸӣеҷЁз”ұ2зө„NVLinkдәӨжҸӣеҷЁжҷ¶зүҮж§ӢжҲҗпјҢдёҰжҸҗдҫӣ144зө„NVLinkз«ҜеӯҗпјҢз„Ўйҳ»еЎһдәӨжҸӣеҠүйҮҸзӯ”14.4 TB/sпјҢзӮәGB200 NVL72зі»зөұжҸҗдҫӣй«ҳй »еҜ¬е’ҢдҪҺ延йҒІиіҮж–ҷдәӨжҸӣиғҪеҠӣгҖӮ
 в–І GB200 NVL72ж©ҹж«ғе…·жңү18зө„GB200 SuperchipйҒӢз®—зҜҖй»һпјҢзёҪе…ұеҢ…еҗ«72зө„Blackwell GPUиҲҮ36зө„Grace CPUгҖӮ
в–І GB200 NVL72ж©ҹж«ғе…·жңү18зө„GB200 SuperchipйҒӢз®—зҜҖй»һпјҢзёҪе…ұеҢ…еҗ«72зө„Blackwell GPUиҲҮ36зө„Grace CPUгҖӮ
 в–І GB200 NVL72ж©ҹж«ғиғҢйқўеүҮжңүзЁұзӮәNVLink SpineпјҲNVLinkи„ҠжӨҺпјүзҡ„иіҮж–ҷйҖЈжҺҘзәңз·ҡпјҢGPUдёІиҒҜеңЁдёҖиө·гҖӮ
в–І GB200 NVL72ж©ҹж«ғиғҢйқўеүҮжңүзЁұзӮәNVLink SpineпјҲNVLinkи„ҠжӨҺпјүзҡ„иіҮж–ҷйҖЈжҺҘзәңз·ҡпјҢGPUдёІиҒҜеңЁдёҖиө·гҖӮ
NVIDIAдёҚдҪҶйҖҸйҒҺCUDAзўәз«ӢдәҶAIйҒӢз®—и»ҹй«”иҲҮжЎҶжһ¶зҡ„й ҳе…Ҳе„ӘеӢўпјҢйҡЁи‘—Blackwellжһ¶ж§ӢжҺЁеҮәзҡ„第5д»ЈNVLinkд№ҹж”ҜжҸҙдёІиҒҜжӣҙеӨҡGPUпјҢйҖІиҖҢжҸҗдҫӣжӣҙйҫҗеӨ§зҡ„йҒӢз®—иғҪеҠӣд»ҘеҸҠиЁҳжҶ¶й«”зёҪе®№йҮҸпјҢ讓競зҲӯе°ҚжүӢжңӣеЎөиҺ«еҸҠгҖӮ
пјҲеӣһеҲ°GTC 2024жҳҘеӯЈе ҙзі»еҲ—е ұе°Һзӣ®йҢ„пјү
еҠ е…ҘTе®ўйӮҰFacebookзІүзөІеңҳ еӣәе®ҡй“ҫжҺҘ 'GTC 24пјҡBlackwellжһ¶ж§Ӣи©іи§ЈпјҒзңӢжҮӮB100гҖҒB200гҖҒGB200гҖҒGB200 NVL72жҲҗе“Ўзҡ„зіҫзөҗз“ңи‘ӣ' жҸҗдәӨ: April 2, 2024, 7:00pm CST