
NVIDIA推出支援Stable Diffusion WebUI的TensorRT運算框架最佳化外掛程式,能夠明顯提升圖像生成的速度。
外掛程式安裝與模型轉換為了要獲得加速的效果,使用者需要完成TensorRT運算框架最佳化外掛程式的安裝,以及Checkpoint或LoRA等模型轉換等前置工作,才能在算圖時發揮加速的效果。
根據NVIDIA的說明,目前外掛程式正式版支援Stable Diffusion 1.5 / 2.1,且可支援套用LoRA小模型與Hires. Fix功能,如果想要使用SDXL版本的模型,則需切換至Stable Diffusion WebUI的Dev分支。由於NVIDIA說明未來會正式將SDXL納入支援,所以目前我們就暫時不討論搶先試用開發中版本的部分。
不過需要注意的是,目前TensorRT外掛程式僅可套用1組LoRA,若套用多組則僅於sd_unet選單指定的單一LoRA有效,造成比較大的使用限制,未來若能支援多組LoRA則可大幅提升方便性。
外掛程式安裝與模型轉換請參考下列圖文說明。其中建議讀者在轉換過程中展開自定選項,並根據需求修改參數。如果需要使用Hires. Fix功能,則需將解析度參數的範圍設定大於目標生成圖像的解析度。
進階設定說明
Min / Optimal / Max batch-size:最小 / 最佳 / 最大批次算圖數量。若顯示記憶體為10GB以下,建議設定為1。若為16GB以上,則可嘗試1~4等數值。
Min / Optimal / Max height:最小 / 最佳 / 最大解析度高度。建議設定512~2048,以利使用Hires. Fix功能。
Min / Optimal / Max width:最小 / 最佳 / 最大解析度寬度。建議設定512~2048。
Min / Optimal / Max prompt token count:最小 / 最佳 / 最大提示詞數量。建議設定75~300。
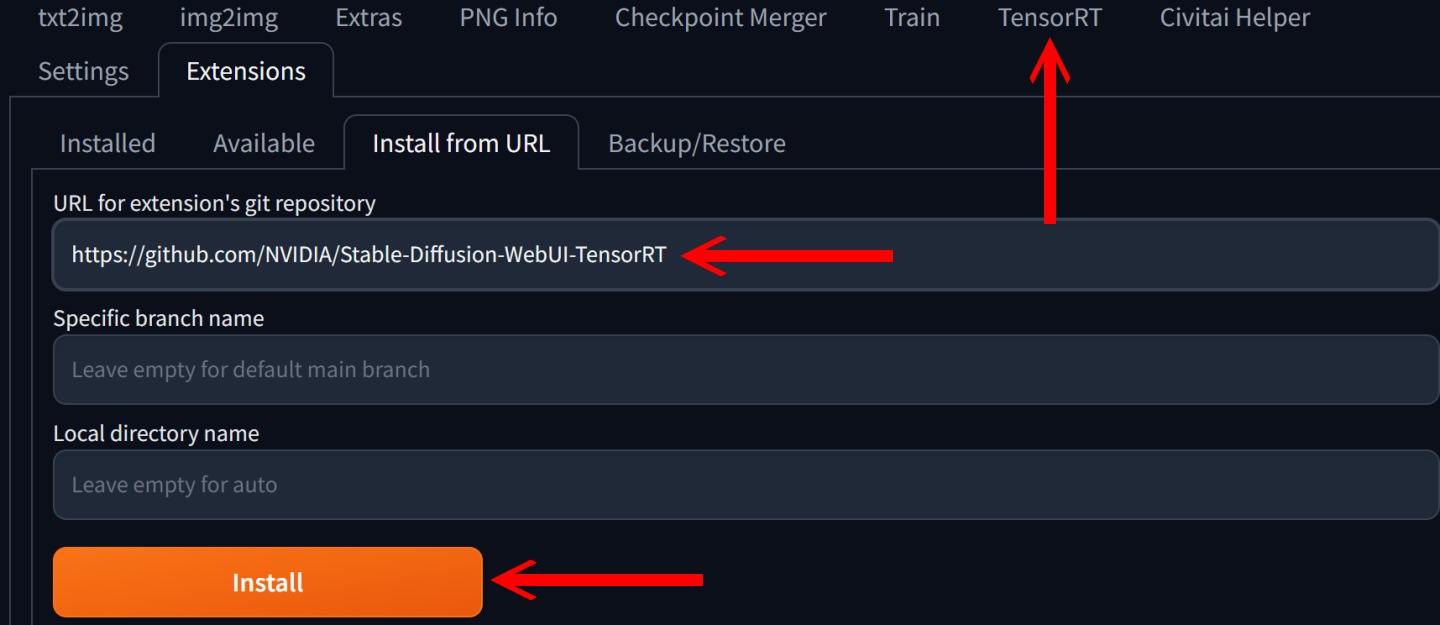 [https:] /> ▲ 外掛程式的安裝相當簡單。開啟Stable Diffusion WebUI介面後,先至Extensions頁面並選擇Install from URL,在URL欄位輸入� [https:]
[https:] /> ▲ 外掛程式的安裝相當簡單。開啟Stable Diffusion WebUI介面後,先至Extensions頁面並選擇Install from URL,在URL欄位輸入� [https:]
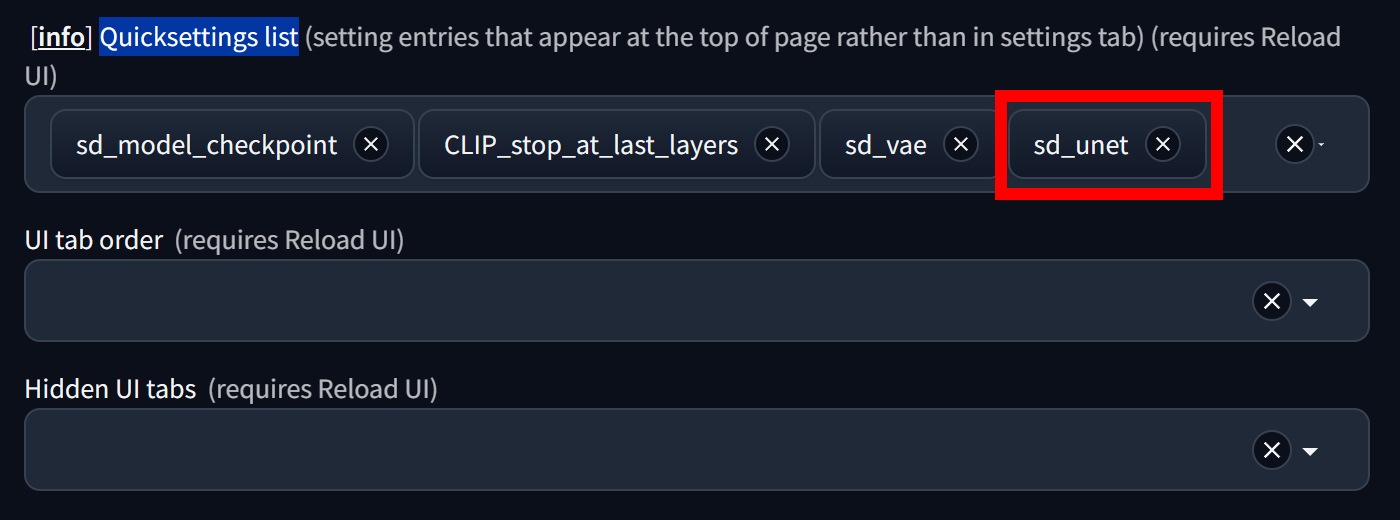 ▲ 接下來到Setting頁面,找到Quicksettings list項目,手動輸入「sd_unet」。完成這2步後,完全關閉Stable Diffusion WebUI再重新開啟。
▲ 接下來到Setting頁面,找到Quicksettings list項目,手動輸入「sd_unet」。完成這2步後,完全關閉Stable Diffusion WebUI再重新開啟。
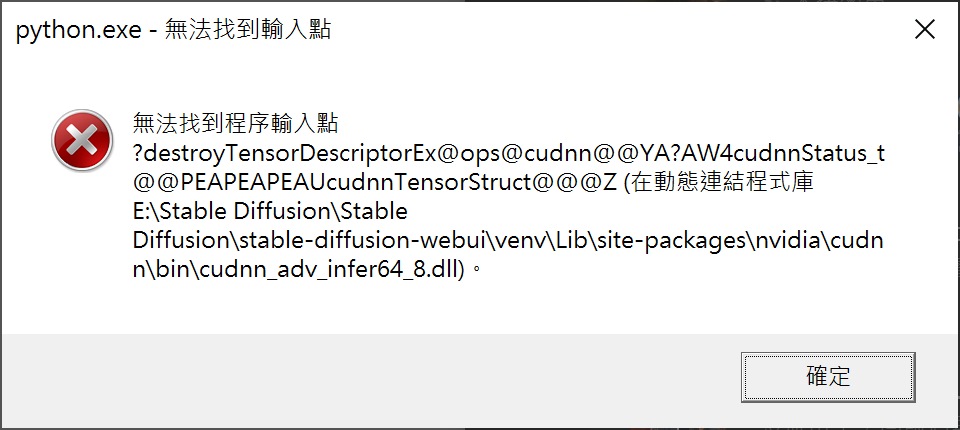 ▲ 目前筆者在開啟程式時會跳出4個缺少檔案的錯誤訊息,但是檢查後檔案都存在。由於不影響後續操作,故略過這些錯誤訊息。
▲ 目前筆者在開啟程式時會跳出4個缺少檔案的錯誤訊息,但是檢查後檔案都存在。由於不影響後續操作,故略過這些錯誤訊息。
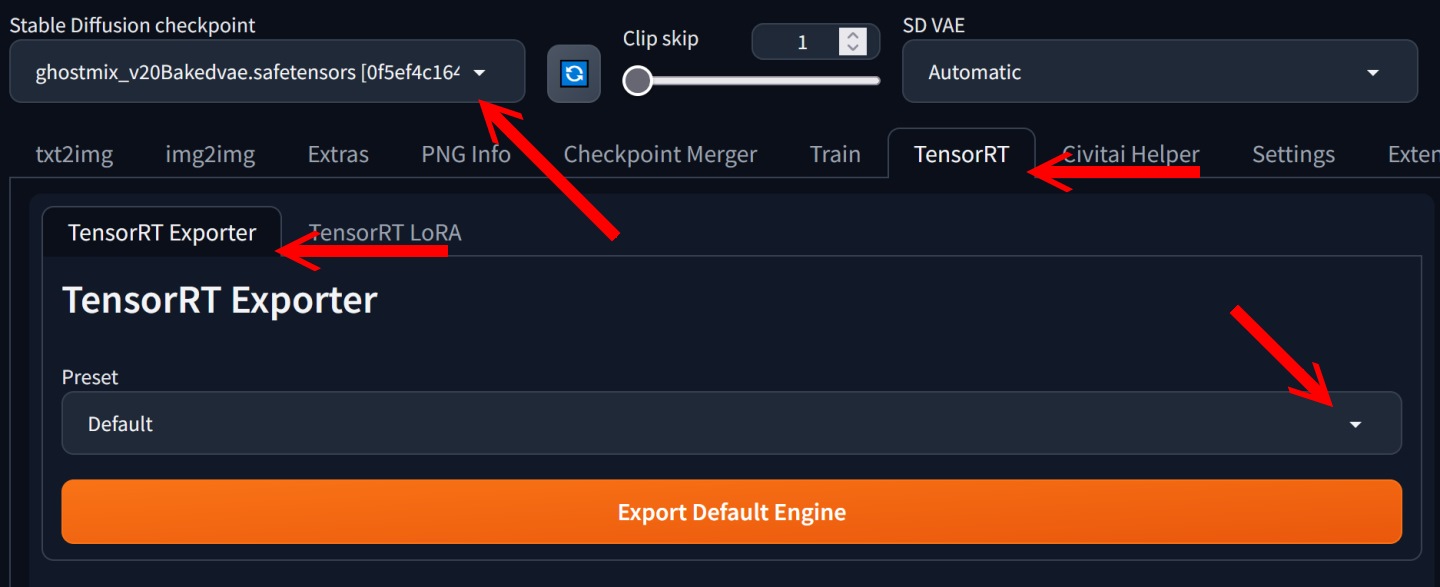 ▲ 重新啟動Stable Diffusion WebUI之後,進入TensorRT標籤下的TensorRT Exporter標籤,在左上角然後選擇Stable Diffusion Checkpoint下拉式選單選擇要轉換的模型,建議在Preset下拉式選單選擇「768x768 - 1024x1024 | Batch Size 1-4 (Dynamic)」,並點選Advanced Settings展開進階設定。
▲ 重新啟動Stable Diffusion WebUI之後,進入TensorRT標籤下的TensorRT Exporter標籤,在左上角然後選擇Stable Diffusion Checkpoint下拉式選單選擇要轉換的模型,建議在Preset下拉式選單選擇「768x768 - 1024x1024 | Batch Size 1-4 (Dynamic)」,並點選Advanced Settings展開進階設定。
 ▲ 進階設定的參考畫面,可依需求調整設定。
▲ 進階設定的參考畫面,可依需求調整設定。
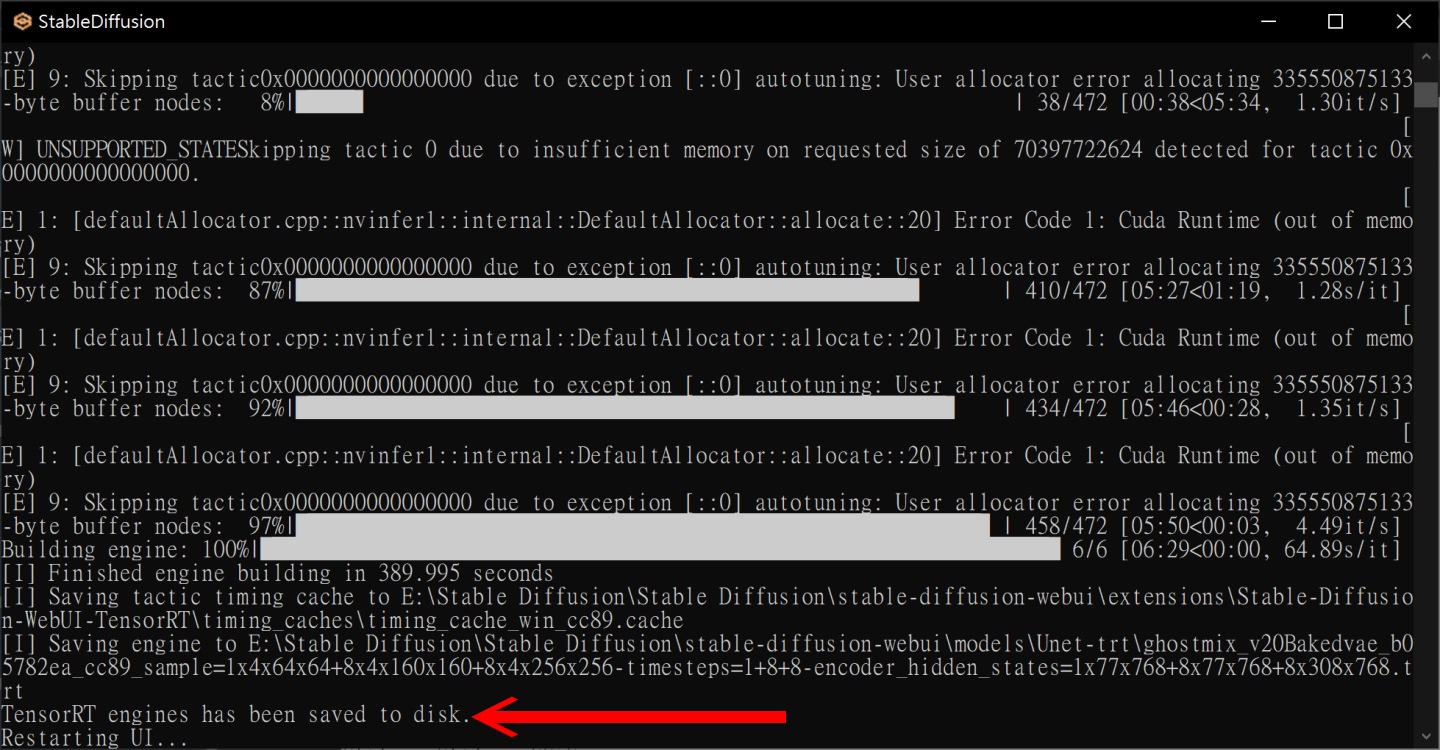 ▲ 設定完成後點擊下方Export Engine按鈕,並等待轉換工作完成。
▲ 設定完成後點擊下方Export Engine按鈕,並等待轉換工作完成。
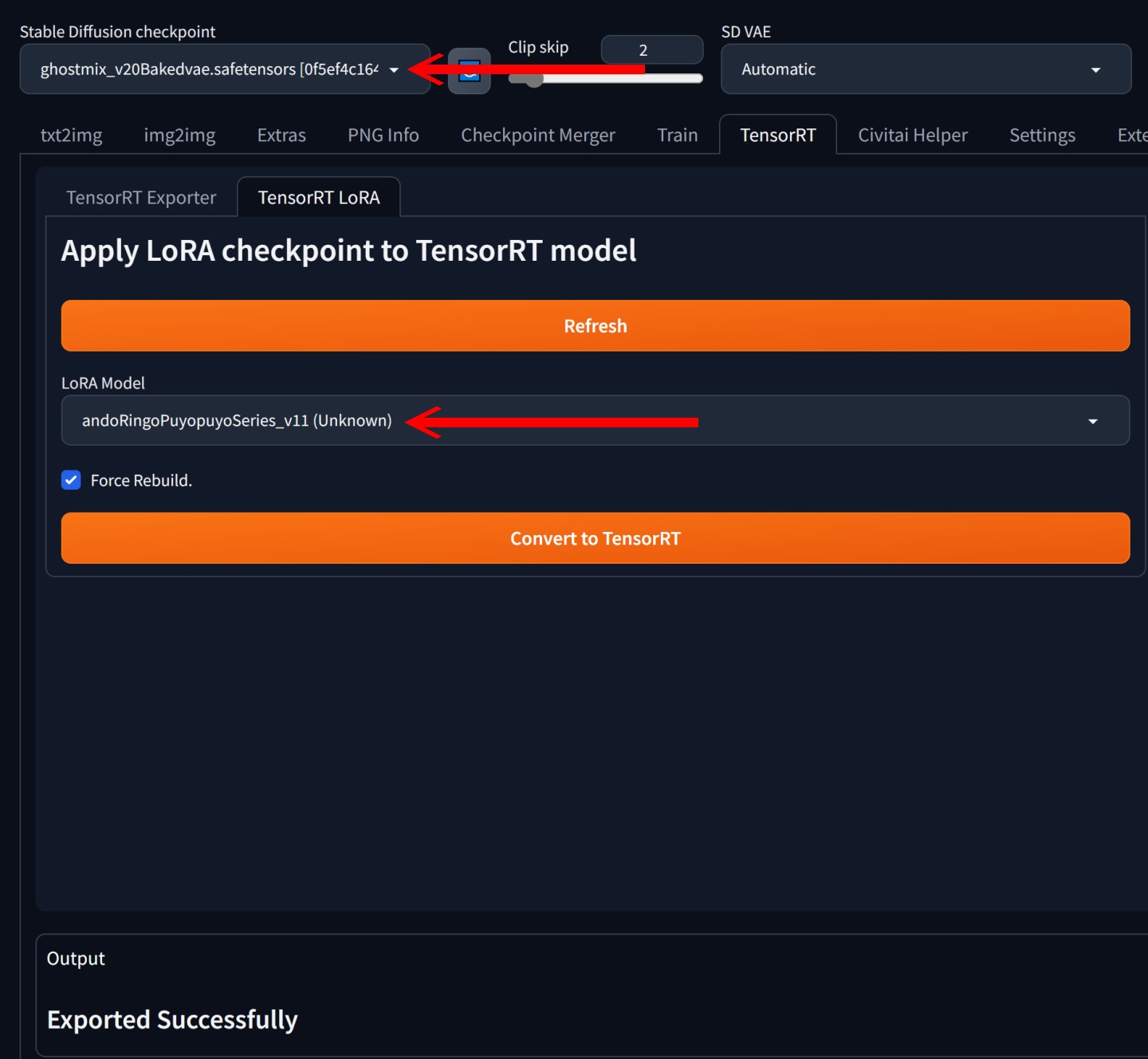 ▲ LoRA的轉換工作比較簡單,進入TensorRT標籤下的TensorRT LoRA標籤,一樣需要在Stable Diffusion Checkpoint選擇要轉換的模型,並在LoRA Model下拉式選單選擇搭配的LoRA,之後點擊Convert to TensorRT按鈕。
▲ LoRA的轉換工作比較簡單,進入TensorRT標籤下的TensorRT LoRA標籤,一樣需要在Stable Diffusion Checkpoint選擇要轉換的模型,並在LoRA Model下拉式選單選擇搭配的LoRA,之後點擊Convert to TensorRT按鈕。
完成前置作業後,使用者只需在Unet下拉式選單中選取指定的Checkpoint或LoRA模型,其餘設定皆依照一般圖像生成即可。
需要注意的是,無論是否使用Hires. Fix功能,在放大前、後的解析度都必需設定為64的整數倍(例如768 x 512,或1920 x 1280),而且需要小於轉換模型時的設定值。
要使用LoRA的話,則需在Unet下拉式選單指定的LoRA,且僅有該組LoRA會在圖像生成時產生作用。若在提示詞中寫入其他LoRA,雖然照樣能夠完成圖像生成並輸出,但該部分提示詞就不會產生作用。
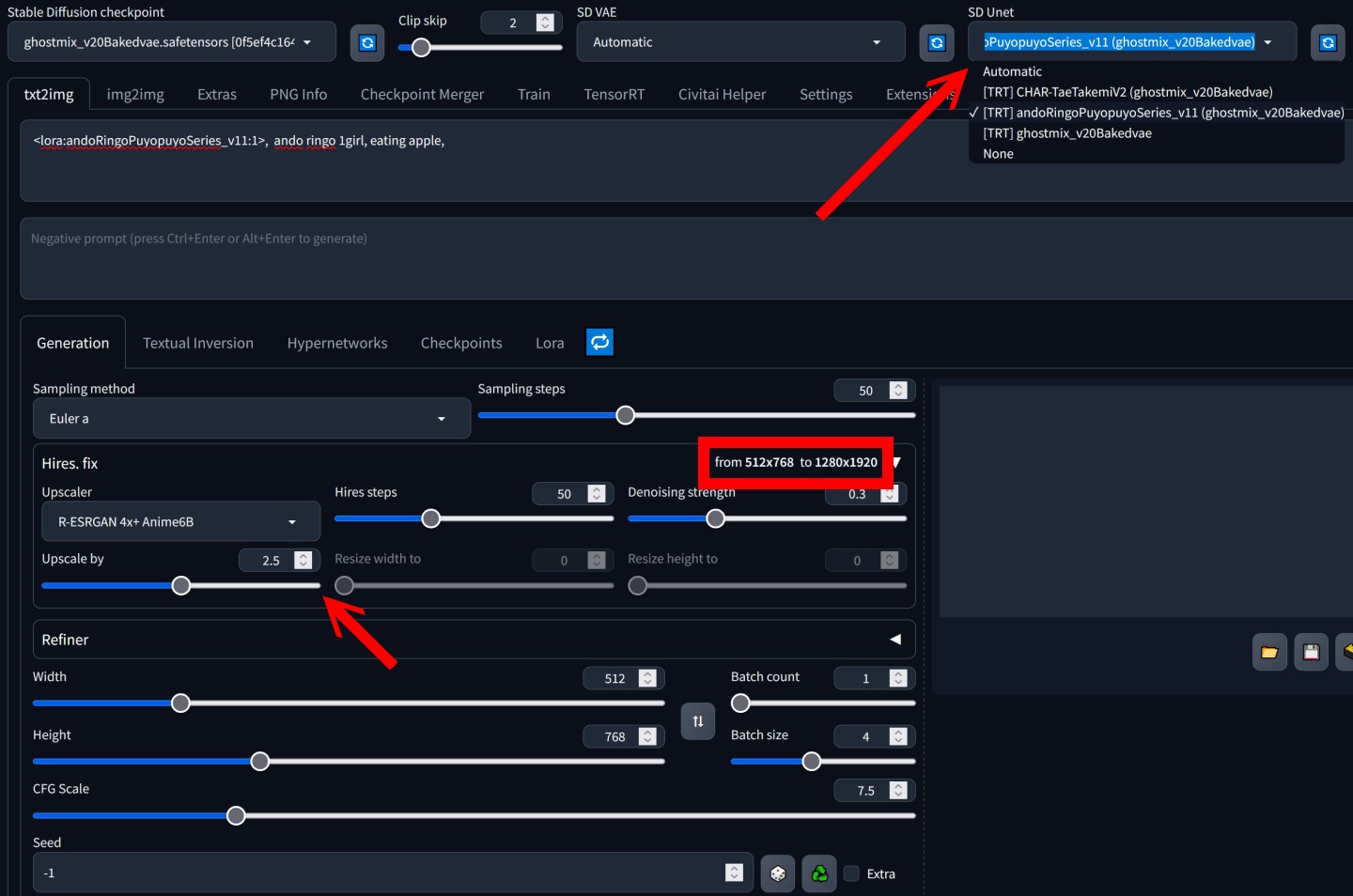 ▲ 如果想要啟用TensorRT,需要在SD Unet下拉式選單中選取指定的Checkpoint或LoRA模型,需要注意只能選擇1組LoRA,其他於提示詞中加入的LoRA不會生效。另一方面,如果要使用Hires. Fix功能的話,放大後的解析度不能超過轉換模型時的設定值。
▲ 如果想要啟用TensorRT,需要在SD Unet下拉式選單中選取指定的Checkpoint或LoRA模型,需要注意只能選擇1組LoRA,其他於提示詞中加入的LoRA不會生效。另一方面,如果要使用Hires. Fix功能的話,放大後的解析度不能超過轉換模型時的設定值。
![若一切�定�常,在算圖時就可看到Activating unst : [TRT]的訊息。](https://cdn1.techbang.com/system/images/697874/original/f98128a65a28f66b7304e44afa99c759.jpg?1700405932) ▲ 若一切設定正常,在算圖時就可看到Activating unst : [TRT]的訊息。
▲ 若一切設定正常,在算圖時就可看到Activating unst : [TRT]的訊息。
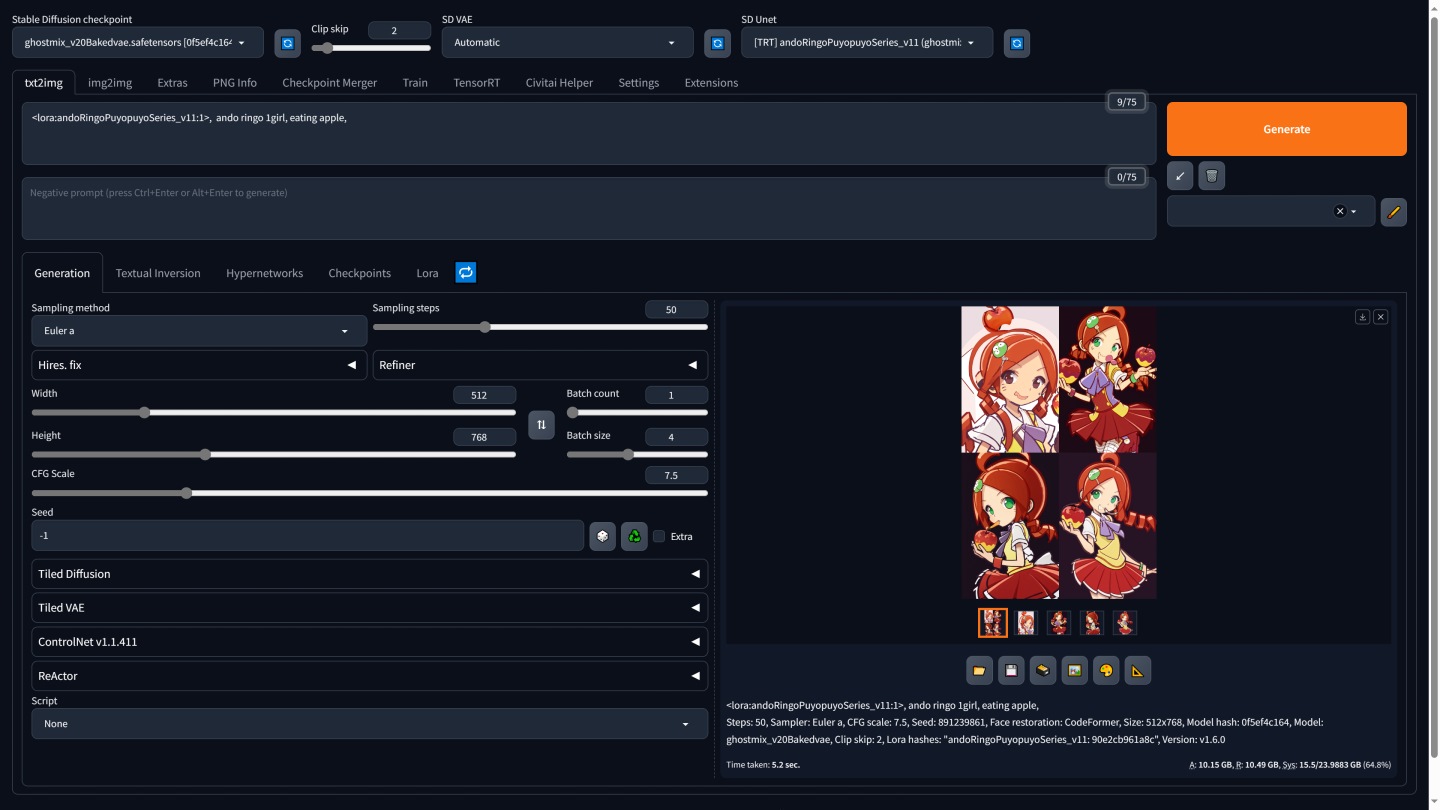 ▲ 經測試驗證,正式版TensorRT外掛程式能夠正確啟用LoRA小模型與Hires. Fix功能。
▲ 經測試驗證,正式版TensorRT外掛程式能夠正確啟用LoRA小模型與Hires. Fix功能。
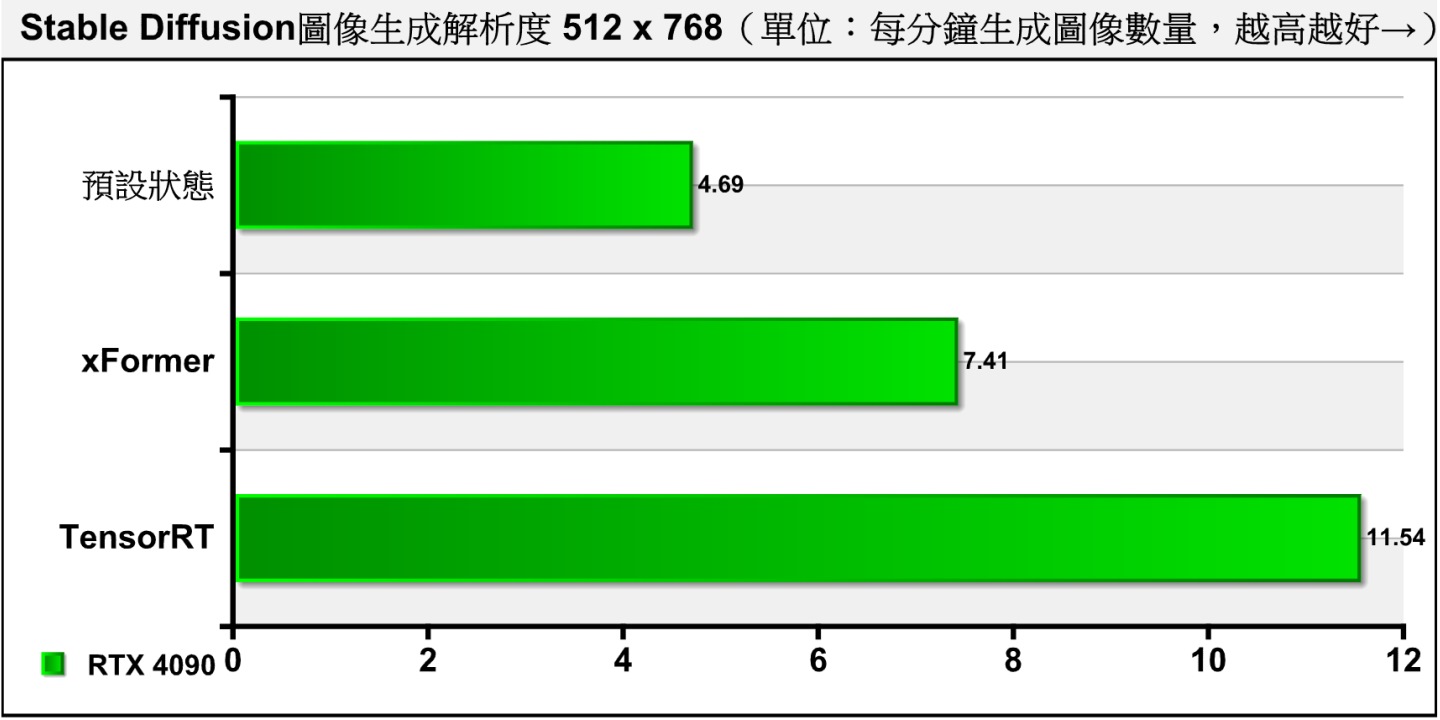 ▲ 在實際測試中,可以看到原有的xFormer可以提升約58%算圖速度,而TensorRT可以提升146%速度,效果更顯著。
▲ 在實際測試中,可以看到原有的xFormer可以提升約58%算圖速度,而TensorRT可以提升146%速度,效果更顯著。
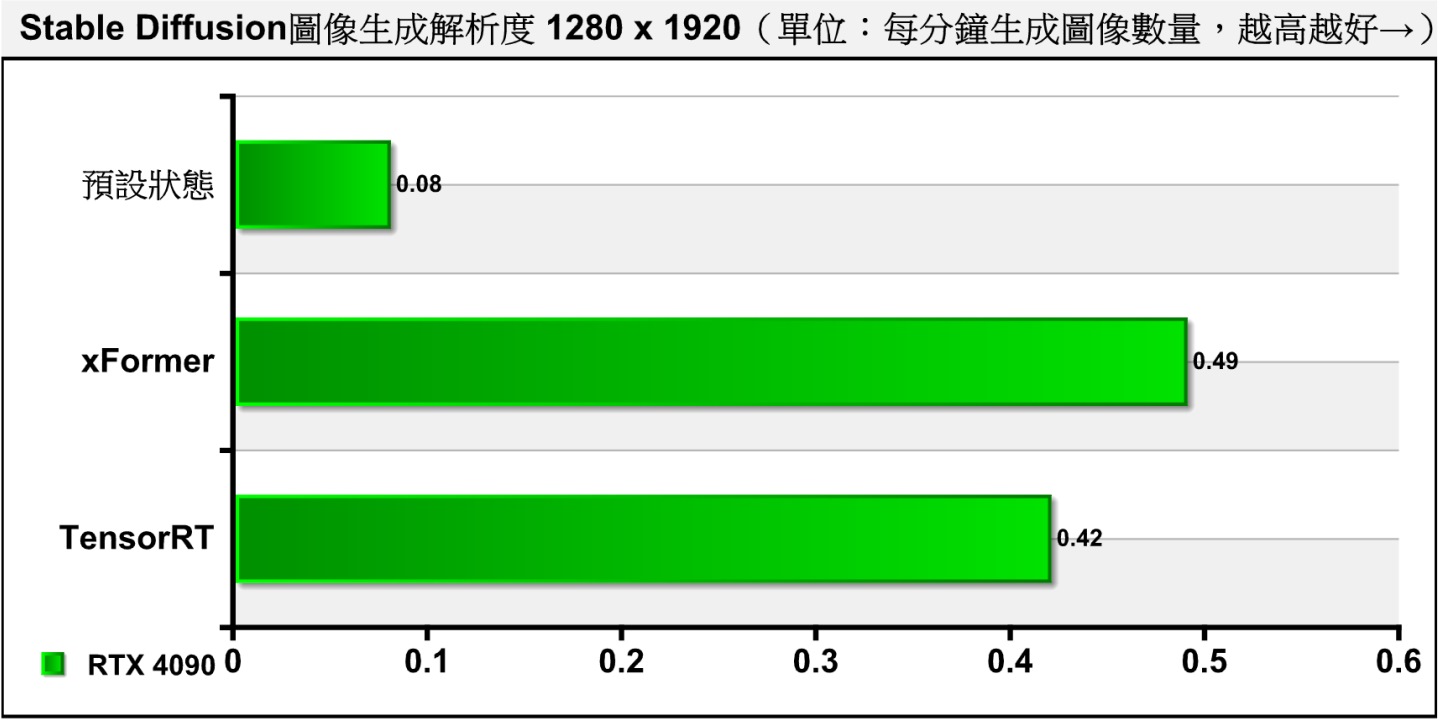 ▲ 不過在使用Hires. Fix功能時,xFormer與TensorRT的效能表現卻差不多。
▲ 不過在使用Hires. Fix功能時,xFormer與TensorRT的效能表現卻差不多。
從測試結果可以看到,TensorRT能在不使用Hires. Fix功能時帶來明顯的加速效果,而在使用時則沒什麼幫助。
與之前的開發中版本相比,這次使用的版本已經可以正確發揮LoRA小模型的效果已經能發揮更大的實用價值,若能套過多組LoRA並提升Hires. Fix效能,則可帶來更大的便利。
(回到系列文章目錄)
加入T客邦Facebook粉絲團 固定链接 'Stable Diffusion AI算圖使用手冊(2-3):NVIDIA正式推出TensorRT運算框架,Checkpoint與LoRA皆可加速' 提交: November 21, 2023, 5:00pm CST