
еңЁз”ҹжҲҗејҸ AI жҷӮд»ЈпјҢGPU зҡ„йҮҚиҰҒжҖ§жҜӢеәёзҪ®з–‘гҖӮNVIDIAиҲҮ AMD йҖҷе…©еҖӢйҮҚйҮҸзҙҡйҒёжүӢжӯЈеңЁзЎ¬й«”гҖҒи»ҹй«”еұӨйқўеұ•й–ӢжҝҖзғҲи§’йҖҗгҖӮВ
еҰӮд»ҠпјҢ當дәәеҖ‘и«Үи«–иө·з”ҹжҲҗејҸ AIпјҲGenAIпјүжҷӮпјҢGPU д»ҘеҸҠзӣёжҮүзҡ„жҖ§иғҪе’ҢйҖ иЁӘжҖ§е№ҫд№ҺжҳҜз№һдёҚйҒҺзҡ„и©ұйЎҢгҖӮиҖҢNVIDIAеҸҲжҳҜ GPU зҡ„д»ЈеҗҚи©һпјҢеңЁеңӢйҡӣ GPU еёӮе ҙдёҠдҪ”ж“ҡзө•е°Қе„ӘеӢўзҡ„еҚ жңүзҺҮгҖӮеҗҢжҷӮпјҢиҝ‘е№ҙдҫҶ AMD д№ҹйҖҗжјёеҙӣиө·пјҢжңүдәҶдёҖе®ҡеёӮе ҙеҚ жңүзҺҮгҖӮВ
дёҚйҒҺпјҢAMD иҲҮNVIDIAд»ҚеӯҳеңЁдёҖе®ҡзҡ„е·®и·қгҖӮд№ӢеүҚеёӮе ҙиӘҝжҹҘз ”з©¶ж©ҹж§Ӣ Jon Peddie Research зҷјиЎЁзҡ„ 2022 е№ҙ GPU еёӮе ҙиіҮж–ҷзөұиЁҲе ұе‘ҠйЎҜзӨәпјҢNVIDIA PC GPU еҮәиІЁйҮҸй«ҳйҒ” 3034 иҗ¬ејөпјҢжҳҜ AMD зҡ„иҝ‘ 4.5 еҖҚгҖӮВ
е°ұNVIDIAиҖҢиЁҖпјҢе…¶ GPU иҲҮз”ҹжҲҗејҸ AI зҡ„з·ҠеҜҶиҒҜ繫зө•йқһеҒ¶з„¶гҖӮдёҖзӣҙд»ҘдҫҶпјҢNVIDIAиӘҚиӯҳеҲ°йңҖиҰҒеҲ©з”Ёе·Ҙе…·е’ҢжҮүз”ЁдҫҶ幫еҠ©жӢ“еұ•иҮӘе·ұзҡ„еёӮе ҙгҖӮеӣ жӯӨпјҢNVIDIAзӮәдәәеҖ‘зҚІеҸ–иҮӘиә«зЎ¬й«”иЁӯзҪ®дәҶйқһеёёдҪҺзҡ„й–ҖжӘ»пјҢеҢ…жӢ¬ CUDA е·Ҙе…·еҢ…е’Ң cuDNN е„ӘеҢ–еә«зӯүгҖӮВ
еңЁиў«зЁұзӮәзЎ¬й«”е…¬еҸёд№ӢеӨ–пјҢжӯЈеҰӮNVIDIAжҮүз”Ёж·ұеәҰеӯёзҝ’з ”з©¶еүҜзёҪиЈҒ Bryan Catanzaro жүҖиЁҖпјҢгҖҢеҫҲеӨҡдәәдёҚзҹҘйҒ“зҡ„дёҖй»һжҳҜпјҢNVIDIAзҡ„и»ҹй«”е·ҘзЁӢеё«жҜ”зЎ¬й«”е·ҘзЁӢеё«йӮ„иҰҒеӨҡгҖӮгҖҚВ
еҸҜд»ҘиӘӘпјҢNVIDIAеңҚз№һе…¶зЎ¬й«”ж§Ӣе»әдәҶеј·еӨ§зҡ„и»ҹй«”иӯ·еҹҺжІігҖӮйӣ–然 CUDA дёҚй–ӢжәҗпјҢдҪҶе…ҚиІ»жҸҗдҫӣпјҢдёҰиҷ•ж–јNVIDIAзҡ„еҡҙж јжҺ§еҲ¶д№ӢдёӢгҖӮNVIDIAеҫһдёӯеҸ—зӣҠпјҢдҪҶд№ҹзөҰйӮЈдәӣеёҢжңӣйҖҸйҒҺй–Ӣзҷјжӣҝд»ЈзЎ¬й«”жҗ¶дҪ” HPC е’Ңз”ҹжҲҗејҸ AI еёӮе ҙзҡ„е…¬еҸёе’ҢдҪҝз”ЁиҖ…её¶дҫҶдәҶжҢ‘жҲ°гҖӮВ
гҖҢеҹҺе Ўең°еҹәгҖҚдёҠзҡ„е»әзҜүВжҲ‘еҖ‘зҹҘйҒ“пјҢзӮәз”ҹжҲҗејҸ AI й–Ӣзҷјзҡ„еҹәзӨҺжЁЎеһӢж•ёйҮҸжҢҒзәҢеўһй•·пјҢе…¶дёӯеҫҲеӨҡжҳҜй–Ӣжәҗзҡ„пјҢеҸҜд»ҘиҮӘз”ұдҪҝз”Ёе’Ңе…ұз”ЁпјҢеҰӮ Meta зҡ„ Llama зі»еҲ—еӨ§жЁЎеһӢгҖӮйҖҷдәӣжЁЎеһӢйңҖиҰҒеӨ§йҮҸиіҮжәҗпјҲеҰӮдәәеҠӣе’Ңж©ҹеҷЁпјүдҫҶж§Ӣе»әпјҢдёҰдё”еұҖйҷҗж–јж“ҒжңүеӨ§йҮҸ GPU зҡ„и¶…еӨ§иҰҸжЁЎдјҒжҘӯпјҢеғҸжҳҜ AWSгҖҒеҫ®и»ҹ AzureгҖҒGoogle CloudгҖҒMeta Platforms зӯүгҖӮжӯӨеӨ–е…¶д»–е…¬еҸёд№ҹиіјиІ·еӨ§йҮҸ GPU дҫҶж§Ӣе»әиҮӘе·ұзҡ„еҹәзӨҺжЁЎеһӢгҖӮВ
еҫһз ”з©¶зҡ„и§’еәҰдҫҶзңӢпјҢйҖҷдәӣжЁЎеһӢеҫҲжңүи¶ЈпјҢеҸҜд»Ҙз”Ёж–јеҗ„зЁ®д»»еӢҷгҖӮдҪҶжҳҜпјҢе°ҚжӣҙеӨҡз”ҹжҲҗејҸ AI иЁҲз®—иіҮжәҗзҡ„й җжңҹдҪҝз”Ёе’ҢйңҖжұӮи¶ҠдҫҶи¶ҠеӨ§пјҢжҜ”еҰӮжЁЎеһӢеҫ®иӘҝе’ҢжҺЁзҗҶпјҢеүҚиҖ…е°Үзү№е®ҡй ҳеҹҹзҡ„иіҮж–ҷеҠ е…ҘеҲ°еҹәзӨҺжЁЎеһӢдёӯпјҢдҪҝд№ӢйҒ©еҗҲиҮӘе·ұзҡ„дҪҝз”ЁжЎҲдҫӢпјӣеҫҢиҖ…еңЁеҫ®иӘҝеҫҢпјҢеҜҰйҡӣдҪҝз”ЁпјҲеҚіе•Ҹе•ҸйЎҢпјүйңҖиҰҒж¶ҲиҖ—иіҮжәҗгҖӮВ
йҖҷдәӣд»»еӢҷйңҖиҰҒеҠ йҖҹйҒӢз®—зҡ„еҸғиҲҮпјҢеҚі GPUгҖӮйЎҜиҖҢжҳ“иҰӢзҡ„и§Јжұәж–№жЎҲжҳҜиіјиІ·жӣҙеӨҡзҡ„NVIDIA GPUгҖӮдҪҶйҡЁи‘—дҫӣдёҚжҮүжұӮпјҢAMD иҝҺдҫҶдәҶеҫҲеҘҪзҡ„ж©ҹжңғгҖӮIntelе’Ңе…¶д»–дёҖдәӣе…¬еҸёд№ҹжә–еӮҷеҘҪйҖІе…ҘйҖҷдёҖеёӮе ҙгҖӮйҡЁи‘—еҫ®иӘҝе’ҢжҺЁзҗҶи®Ҡеҫ—жӣҙеҠ жҷ®йҒҚпјҢз”ҹжҲҗејҸ AI е°Үз№јзәҢж“ еЈ“ GPU зҡ„еҸҜз”ЁжҖ§пјҢйҖҷжҷӮдҪҝз”Ёд»»дҪ• GPUпјҲжҲ–еҠ йҖҹеҷЁпјүйғҪжҜ”жІ’жңү GPU еҘҪгҖӮВ
ж”ҫжЈ„NVIDIAзЎ¬й«”ж„Ҹе‘іи‘—е…¶д»–дҫӣжҮүе•Ҷзҡ„ GPU е’ҢеҠ йҖҹеҷЁеҝ…й Ҳж”ҜжҸҙ CUDA жүҚиғҪйҒӢиЎҢеҫҲеӨҡжЁЎеһӢе’Ңе·Ҙе…·гҖӮAMDйҖҸйҒҺ HIPпјҲйЎһ CUDAпјүиҪүжҸӣе·Ҙе…·дҪҝйҖҷдёҖжғ…жіҒжҲҗзӮәеҸҜиғҪгҖӮВ
- 延伸й–ұи®ҖпјҡNVIDIAжүҚжҳҜжҗһз”ҹжҲҗејҸAIзҡ„еӨ§зҺ©е®¶пјҢе®ЈеёғжҺЁеҮәNVIDIA AI WorkbenchпјҡжҠҠз”ҹжҲҗејҸAIе·ҘдҪңзҡ„дёҖеҲҮдёҖйҚөжү“еҢ…её¶иө°
еңЁ HPC й ҳеҹҹпјҢж”ҜжҸҙ CUDA зҡ„жҮүз”ЁзЁӢејҸзөұжІ»и‘— GPU еҠ йҖҹзҡ„дё–з•ҢгҖӮдҪҝз”Ё GPU е’Ң CUDA жҷӮпјҢ移жӨҚзЁӢејҸзўјйҖҡеёёеҸҜд»ҘеҜҰзҸҫ 5-6 еҖҚзҡ„еҠ йҖҹгҖӮдҪҶеңЁз”ҹжҲҗејҸ AI дёӯпјҢжғ…жіҒеҚ»жҲӘ然дёҚеҗҢгҖӮВ
жңҖй–Ӣе§ӢпјҢTensorFlow жҳҜдҪҝз”Ё GPU еүөе»ә AI жҮүз”Ёзҡ„йҰ–йҒёе·Ҙе…·пјҢе®ғж—ўеҸҜд»ҘиҲҮ CPU й…ҚеҗҲдҪҝз”ЁпјҢд№ҹиғҪеӨ йҖҸйҒҺ CUDA еҜҰзҸҫеҠ йҖҹгҖӮдёҚйҒҺпјҢйҖҷдёҖжғ…жіҒжӯЈеңЁеҝ«йҖҹзҷјз”ҹж”№и®ҠгҖӮВ
PyTorch жҲҗзӮәдәҶ TensorFlow зҡ„еј·жңүеҠӣжӣҝд»Је“ҒпјҢдҪңзӮәдёҖеҖӢй–Ӣжәҗж©ҹеҷЁеӯёзҝ’еә«пјҢе®ғдё»иҰҒз”Ёж–јй–Ӣзҷје’ҢиЁ“з·ҙеҹәж–јзҘһ經網и·Ҝзҡ„ж·ұеәҰеӯёзҝ’жЁЎеһӢгҖӮВ
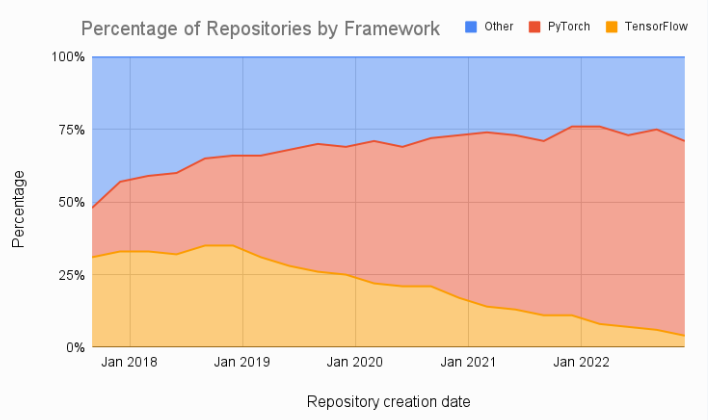
жңҖиҝ‘ AssemblyAI зҡ„дёҖдҪҚй–ӢзҷјиҖ… educator Ryan OвҖҷConnor еңЁдёҖзҜҮйғЁиҗҪж јж–Үз« дёӯжҢҮеҮәпјҢеңЁжөҒиЎҢзҡ„ HuggingFace з¶Із«ҷдёҠпјҢ92% зҡ„еҸҜз”ЁжЁЎеһӢйғҪжҳҜ PyTorch зҚЁжңүзҡ„гҖӮВ
жӯӨеӨ–еҰӮдёӢең–жүҖзӨәпјҢж©ҹеҷЁеӯёзҝ’и«–ж–Үзҡ„жҜ”ијғд№ҹйЎҜзӨәеҮәж”ҫжЈ„ TensorFlowгҖҒиҪүжҠ• PyTorch зҡ„йЎҜи‘—и¶ЁеӢўгҖӮВ
當然пјҢPyTorch еә•еұӨе‘јеҸ« CUDA пјҢдҪҶдёҚжҳҜеҝ…йңҖзҡ„пјҢйҖҷжҳҜеӣ зӮә PyTorch е°ҮдҪҝз”ЁиҖ…иҲҮеә•еұӨ GPU жһ¶ж§Ӣйҡ”йӣўй–ӢдҫҶгҖӮAMD йӮ„жңүдёҖеҖӢдҪҝз”Ё AMD ROCm зҡ„ PyTorch зүҲжң¬пјҢе®ғжҳҜдёҖеҖӢз”Ёж–ј AMD GPU зЁӢејҸиЁӯиЁҲзҡ„й–Ӣжәҗи»ҹй«”е Ҷз–ҠгҖӮВ
зҸҫеңЁпјҢе°Қж–ј AMD GPU иҖҢиЁҖпјҢи·Ёи¶Ҡ CUDA иӯ·еҹҺжІіе°ұеғҸдҪҝз”Ё PyTorch дёҖжЁЈз°Ўе–®гҖӮВ
- 延伸й–ұи®ҖпјҡNVIDIAй»ғд»ҒеӢіпјҡйӣ»и…ҰйҒӢ算已經жңүж №жң¬дёҠж”№и®ҠпјҢеҶҚиІ·дёҖеӨ§е ҶCPUжҜ«з„Ўж„Ҹзҫ©
еңЁ HPC е’Ңз”ҹжҲҗејҸ AI дёӯпјҢй…Қжңү H100 GPU е…ұз”ЁиЁҳжҶ¶й«”зҡ„NVIDIA 72 ж ёгҖҒдё”еҹәж–ј ARM зҡ„ Grace-Hopper и¶…зҙҡжҷ¶зүҮпјҲд»ҘеҸҠ 144 ж ё Grace-Grace зүҲжң¬пјүеӮҷеҸ—жңҹеҫ…гҖӮВ
иҝ„д»ҠпјҢNVIDIAзҷјиЎЁзҡ„жүҖжңүеҹәжә–жё¬и©ҰиЎЁжҳҺпјҢи©Іжҷ¶зүҮзҡ„жҖ§иғҪжҜ”йҖҸйҒҺ PCIe еҢҜжөҒжҺ’йҖЈжҺҘе’ҢеӯҳеҸ–GPU зҡ„еӮізөұдјәжңҚеҷЁиҰҒеҘҪеҫ—еӨҡгҖӮGrace-Hopper жҳҜйқўеҗ‘ HPC е’Ңз”ҹжҲҗејҸ AI зҡ„жңҖдҪіеҢ–зЎ¬й«”пјҢжңүжңӣеңЁеҫ®иӘҝе’ҢжҺЁзҗҶж–№йқўеҫ—еҲ°е»ЈжіӣжҮүз”ЁпјҢйңҖжұӮй җиЁҲжңғеҫҲй«ҳгҖӮВ
иҖҢ AMD еҫһ 2006 е№ҙпјҲдәҺ當е№ҙ收購дәҶйЎҜзӨәеҚЎе…¬еҸё ATIпјүе°ұ已經еҮәзҸҫдәҶеё¶жңүе…ұз”ЁиЁҳжҶ¶й«”зҡ„ CPU-GPU иЁӯиЁҲгҖӮеҫһ Fusion е“ҒзүҢй–Ӣе§ӢпјҢеҫҲеӨҡ AMD x86_64 иҷ•зҗҶеҷЁйғҪдҪңзӮә APUпјҲеҠ йҖҹиҷ•зҗҶе–®е…ғпјүзҡ„зө„еҗҲ CPU/GPU дҫҶеҜҰзҸҫгҖӮВ
AMD жҺЁеҮәзҡ„ Instinct MI300A иҷ•зҗҶеҷЁпјҲAPUпјүе°ҮиҲҮNVIDIAзҡ„ Grace-Hopper и¶…зҙҡжҷ¶зүҮеұ•й–Ӣ競зҲӯгҖӮж•ҙеҗҲзҡ„ MI300A иҷ•зҗҶеҷЁе°ҮжңҖеӨҡжҸҗдҫӣ 24 еҖӢ Zen4 ж ёеҝғпјҢдёҰзөҗеҗҲ CDNA 3 GPU жһ¶ж§Ӣе’ҢжңҖеӨҡ 192GB зҡ„ HBM3 иЁҳжҶ¶й«”пјҢзӮәжүҖжңү CPU е’Ң GPU ж ёеҝғжҸҗдҫӣдәҶзөұдёҖзҡ„йҖ иЁӘиЁҳжҶ¶й«”гҖӮВ
еҸҜд»ҘиӘӘпјҢжҷ¶зүҮзҙҡеҝ«еҸ–дёҖиҮҙжҖ§иЁҳжҶ¶й«”жёӣе°‘дәҶ CPU е’Ң GPU д№Ӣй–“зҡ„иіҮж–ҷ移еӢ•пјҢж¶ҲйҷӨдәҶ PCIe еҢҜжөҒжҺ’з“¶й ёпјҢжҸҗеҚҮдәҶжҖ§иғҪе’ҢиғҪж•ҲгҖӮВ

AMD жӯЈеңЁзӮәжЁЎеһӢжҺЁзҗҶеёӮе ҙжә–еӮҷ MI300A иҷ•зҗҶеҷЁгҖӮеҰӮ AMD CEO иҳҮе§ҝдё°жүҖиЁҖпјҢгҖҢеҜҰйҡӣдёҠпјҢеҫ—зӣҠж–јжһ¶ж§ӢдёҠзҡ„дёҖдәӣйҒёж“ҮпјҢжҲ‘еҖ‘иӘҚзӮәиҮӘе·ұе°ҮжҲҗзӮәжҺЁзҗҶи§Јжұәж–№жЎҲзҡ„иЎҢжҘӯй ҳе°ҺиҖ…гҖӮгҖҚВ
е°Қж–ј AMD е’ҢеҫҲеӨҡе…¶д»–зЎ¬й«”дҫӣжҮүе•ҶиҖҢиЁҖпјҢPyTorch 已經еңЁеңҚз№һеҹәзӨҺжЁЎеһӢзҡ„ CUDA иӯ·еҹҺжІідёҠж”ҫдёӢдәҶеҗҠж©ӢгҖӮAMD зҡ„ Instinct MI300A иҷ•зҗҶеҷЁе°Үжү“й ӯйҷЈгҖӮВ
з”ҹжҲҗејҸ AI еёӮе ҙзҡ„зЎ¬й«”д№ӢжҲ°е°ҮжҶ‘и—үжҖ§иғҪгҖҒеҸҜж”ңжҖ§е’ҢеҸҜз”ЁжҖ§зӯүеӨҡеӣ зҙ дҫҶеҸ–еӢқгҖӮжңӘдҫҶй№ҝжӯ»иӘ°жүӢпјҢе°ҡжңӘеҸҜзҹҘгҖӮВ
- 延伸й–ұи®ҖпјҡNVIDIA Q2ж·ЁеҲ©жҪӨжҡҙжјІ843%пјҢеёӮеҖји¶…йҒҺ8еҖӢIntel
иіҮж–ҷдҫҶжәҗпјҡ
еҠ е…ҘTе®ўйӮҰFacebookзІүзөІеңҳ еӣәе®ҡй“ҫжҺҘ 'GPUжҡҙеўһзҡ„GenAIжҷӮд»ЈпјҢAMDжӯЈеңЁи·Ёи¶ҠNVIDIAжүҖе»әз«Ӣзҡ„CUDAи»ҹй«”иӯ·еҹҺжІі' жҸҗдәӨ: October 10, 2023, 5:00pm CST