
傳說中的 NVIDIAGH200 在 MLPerf 3.1 中驚豔亮相,性能直接碾壓 H100,領先了 17%。繼 4 月份加入 LLM 訓練測試後,MLPerf 再次迎來重磅更新,MLCommons 發布了 MLPerf v3.1版本更新,並加入了兩個全新基準:LLM 推理測試 MLPerf Inference v3.1,以及儲存性能測試 MLPerf Storage v0.5。
這也是 NVIDIA GH200 測試成績的首次亮相!
相比於單張H100配合 Intel CPU,GH200 的 Grace CPU+H100 GPU 的組合,在各個項目上都有 15% 左右的提升。


具體來說,它將一個 H100 GPU 和 Grace CPU 內建在一起,通過 900GB/s 的 NVLink-C2C 連接。
而 CPU 和 GPU 分別配備了 480GB 的 LPDDR5X 記憶體和 96GB 的 HBM3 或者 144GB 的HBM3e 的記憶體,內建了高達 576GB 以上的高速記憶體。
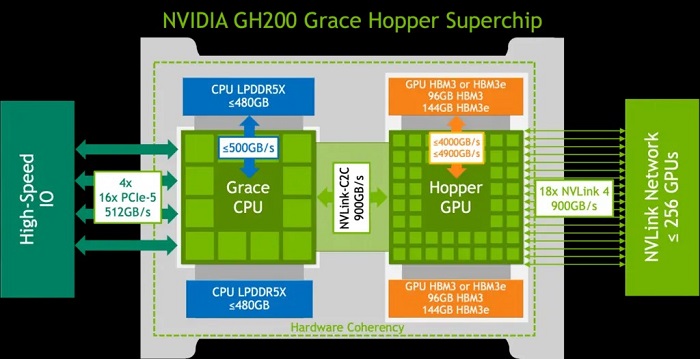
NVIDIAGH200 Grace Hopper 超級晶片專為計算密集型工作負載而設計,能夠滿足各種嚴苛的要求和各項功能。
比如訓練和運行數兆參數的大型 Transformer 模型,或者是運行具有數 TB 大小的嵌入表的推薦系統和向量資料庫。
GH200 Grace Hopper 超級晶片還在 MLPerf Inference 測試中有著非常優異的表現,刷新了 NVIDIA 單個 H100 SXM 在每個項目中創下的最佳成績。
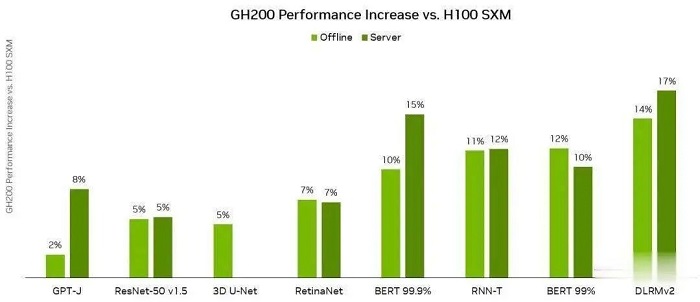
NVIDIA Grace Hopper MLPerf Inference 資料中心性能與 DGX H100 SXM 的對比結果,每個數值都是 GH200 的性能領先幅度
GH200 Grace Hopper 超級晶片內建了 96 GB 的 HBM3,並提供高達 4 TB/s 的 HBM3 記憶體頻寬,而 H100 SXM 分別為 80 GB 和 3.35 TB/s。
與 H100 SXM 相比,更大的記憶體容量和更大的記憶體頻寬使得在 NVIDIA GH200 Grace Hopper 超級晶片上使用更大的批次處理大小來處理工作負載。
例如,在伺服器場景中,RetinaNet 和 DLRMv2 的批次處理大小都增加了一倍,在離線場景中,大小增加了 50%。
GH200 Grace Hopper 超級晶片在 Hopper GPU 和 Grace CPU 之間的高頻寬 NVLink-C2C 連接可以實現 CPU 和 GPU 之間的快速通訊,從而有助於提高性能。
例如,在 MLPerf DLRMv2 中,在 H100 SXM 上通過 PCIe 傳輸一批張量(Tensor)大約需要 22% 的批次處理推理時間。
使用了 NVLink-C2C 的 GH200 Grace Hopper 超級晶片僅使用 3% 的推理時間就完成了相同的傳輸。
由於具有更高的記憶體頻寬和更大的記憶體容量,與 MLPerf Inference v3.1 的 H100 GPU 相比,Grace Hopper 超級晶片的單晶片性能優勢高達 17%。
推理和訓練全面領先在 MLPerf 的首秀中,GH200 Grace Hopper Superchip 在封閉類別(Closed Division)的所有工作負載和場景上都表現出卓越的性能。
而在主流的伺服器應用中,L4 GPU 能夠提供一個低功耗,緊湊型的算力解決方案,與 CPU 解決方案相比的性能也有了大幅的提升。
與測試中最好的 x86 CPU 相比,L4 的性能也非常強勁,提高了 6 倍。

對於其他的 AI 應用和機器人應用,Jetson AGX Orin 和 Jetson Orin NX 模組實現了出色的性能。
未來的軟體最佳化有助於進一步釋放強大的 NVIDIAOrin SoC 在這些模組中的潛力。
在目前非常流行的目標檢測 AI 網路 — RetinaNet 上,NVIDIA 的產品的性能提高了高達84%。
NVIDIA 開放部分(Open Division)的結果,展示了通過模型最佳化可以在保持極高精度的同時大幅提高推理性能的潛力。
全新 MLPerf 3.1 基準測試
當然,這並不是 MLCommons 第一次嘗試對大型語言模型的性能進行基準測試。
早在今年 6 月,MLPerf v3.0 就首次加入了 LLM 訓練的基準測試。不過,LLM 的訓練和推理任務,區別很大。
推理工作負載對計算要求高,而且種類繁多,這就要求平台能夠快速處理各種類型的資料預測,並能在各種 AI 模型上進行推理。
對於希望部署 AI 系統的企業來說,需要一種方法來客觀評估基礎設施在各種工作負載、環境和部署場景中的性能。
所以對於訓練和推理的基準測試都是很重要的。
MLPerf Inference v3.1 包括了兩項重要更新,來更好地反映現在 AI 實際的使用情況:
首先,增加了基於 GPT-J 的大型語言模型 (LLM)推理的測試。GPT-J 是一個開放原始碼的 6B 參數 LLM,對 CNN/每日郵報資料集進行文字總結。
除了 GPT-J 之外,這次還更新了 DLRM 測試。
針對 MLPerf Training v3.0 中引入的 DLRM,採用了新的模型架構和更大的資料集,更好地反映了推薦系統的規模和複雜性。
MLCommons 創始人兼執行董事 David Kanter 表示:訓練基準側重於更大規模的基礎模型,而推理基準執行的實際任務,則代表了更廣泛的用例,大部分組織都可以進行部署。
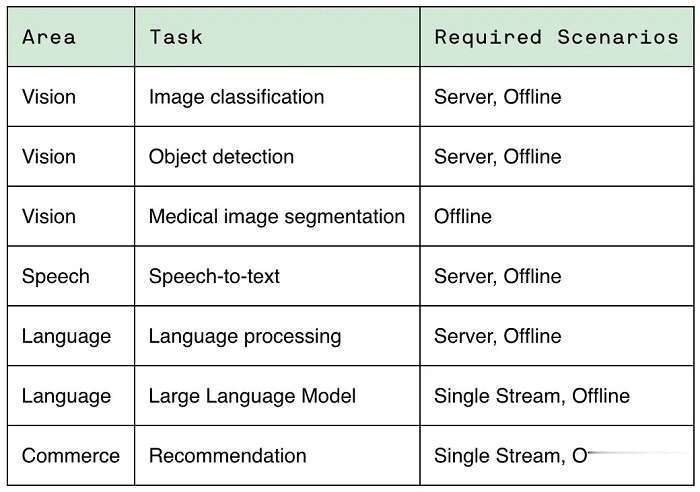
在這方面,為了能夠對各種推理平台和用例進行有代表性的測試,MLPerf 定義了四種不同的場景。
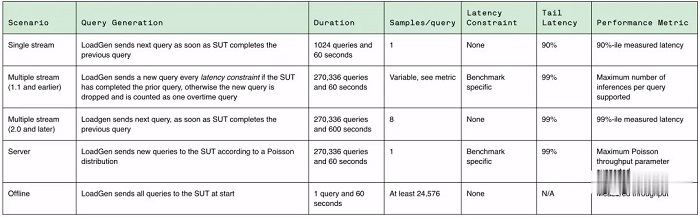
每個基準都由資料集和品質目標定義。
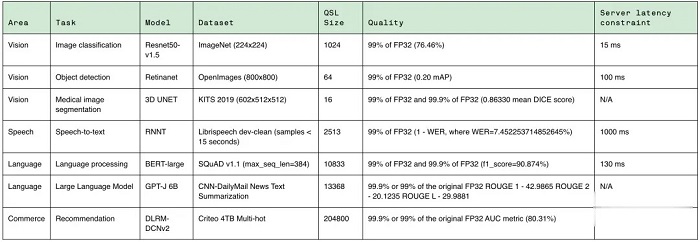
每個基準都需要以下場景:
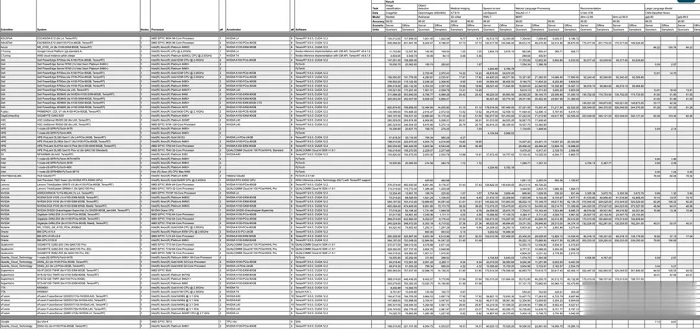
在 MLPerf v3.1 基準測試中,有超過 13,500 個結果,其中不少提交者的性能比 3.0 基準提高了 20%,甚至更多。
其他提交者包括華碩,Azure,cTuning,Connect Tech,Dell,富士通,Giga Computing,Google,H3C,HPE,IEI,Intel,Intel Habana Labs,Krai,聯想,墨芯,Neural Magic,Nutanix,甲骨文,高通,Quanta Cloud Technology,SiMA,Supermicro,TTA 和 xFusion 等。
- 延伸閱讀:NVIDIA本季度H100 AI GPU出貨重達900公噸,估算相當於30萬片
- 延伸閱讀:NVIDIA公布MLPerf v3.1推論測試成績,GH200首次亮相校能最高較H100提升17%
- 延伸閱讀:NVIDIA H100 明年出貨至少增長兩倍,AI 晶片拖累科技公司收益
加入T客邦Facebook粉絲團 固定链接 '碾壓 H100!NVIDIA GH200 超級AI晶片首秀,性能躍升 17%' 提交: October 1, 2023, 4:30pm CST