
GPT-5的訓練,需要5萬張H100加持。NVIDIA GPU已成為各大AI公司開發大模型的首選利器。然而,Sam Altaman自己都說了GPU很缺的問題,竟然不希望太多人用ChatGPT。
「誰將獲得多少H100,何時獲得H100,都是矽谷中最熱門的話題。」

 ▲ OpenAI聯合創始人兼職科學家Andrej Karpathy近日發文,闡述了自己對NVIDIAGPU短缺的看法。
▲ OpenAI聯合創始人兼職科學家Andrej Karpathy近日發文,闡述了自己對NVIDIAGPU短缺的看法。
近來,AI社群中廣為流傳的一張關於「我們需要多少張GPU」的分析,引發了眾多網友的討論。

根據文中內容所示:
- GPT-4可能在大約10000-25000張A100上進行了訓練
- Meta大約21000 A100
- Tesla大約7000 A100
- Stability AI大約5000 A100
- Falcon-40B在384個A100上進行了訓練
– Inflection使用了3500和H100,來訓練與GPT-3.5能力相當的模型
另外,根據馬斯克的說法,GPT-5可能需要30000-50000個H100。
先前,摩根史坦利曾表示估計GPT-5使用25000個GPU,自2月以來已經開始訓練,不過Sam Altman之後澄清了這件事,表示GPT-5尚未進行訓練。
不過,Altman先前曾說過,「我們的GPU非常短缺,使用我們產品的人越少越好。」「如果人們用的越少,我們會很開心,因為我們沒有足夠的GPU。」
在一篇名為《NVIDIA H100 GPU:供需》文章中,深度剖析了當前科技公司們對GPU的使用情況和需求。
文章中推測,小型和大型雲端提供商的大規模H100叢集容量在現今AI狂潮下即將耗盡,H100的需求趨勢至少會持續到2024年底。

那麼,GPU需求真的是遇到了瓶頸嗎?
目前生成式AI爆發仍舊沒有放緩,對算力提出了更高的要求。一些初創公司都在使用NVIDIA昂貴、且性能極高的H100來訓練模型。
馬斯克表示:「GPU在這一點上,比藥物更難獲得。」

上週,微軟發佈了年度報告,並向投資者強調,GPU是其雲端業務快速增長的「關鍵原料」。如果無法獲得所需的基礎設施,可能會出現資料中心中斷的風險因素。
根據分析師統計,OpenAI可能需要50000個H100,而Inflection需要22,000個,Meta可能需要 25k,而大型雲服務商可能需要30k(比如Azure、Google Cloud、AWS、Oracle)。
「Lambda和CoreWeave以及其他私有雲可能總共需要100k。」他寫道:「Anthropic、Helsing、Mistral和Character 可能各需要10k」但這些完全是粗略估計和猜測,其中有些是重複計算雲和從雲租用裝置的最終客戶。

整體算來,全球公司需要約432000張H100。按每個H100約35k美元來計算,GPU總需求耗資150億美元。
這其中還不包括中國,由於受到美國制裁的影響,他們無法取得H100。
包括OpenAI、Anthropic、DeepMind、Google,以及X.ai在內的所有大型實驗室都在進行大型語言模型的訓練,而NVIDIA的H100是無可替代的。
H100為什麼成首選?H100比A100更受歡迎,成為首選,部分原因是快取延遲更低和FP8計算。因為它的效率高達3倍,但成本只有(1.5-2倍)。考慮到整體系統成本,H100的性能要高得多。從技術細節來說,比起A100,H100在16位推理速度大約快3.5倍,16位訓練速度大約快2.3倍。
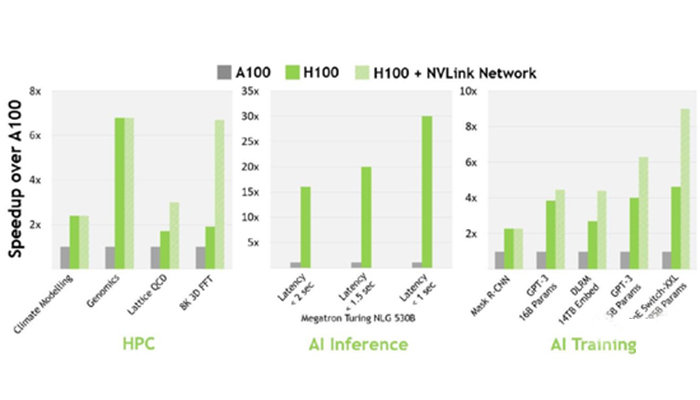 ▲ A100 vs H100速度
▲ A100 vs H100速度
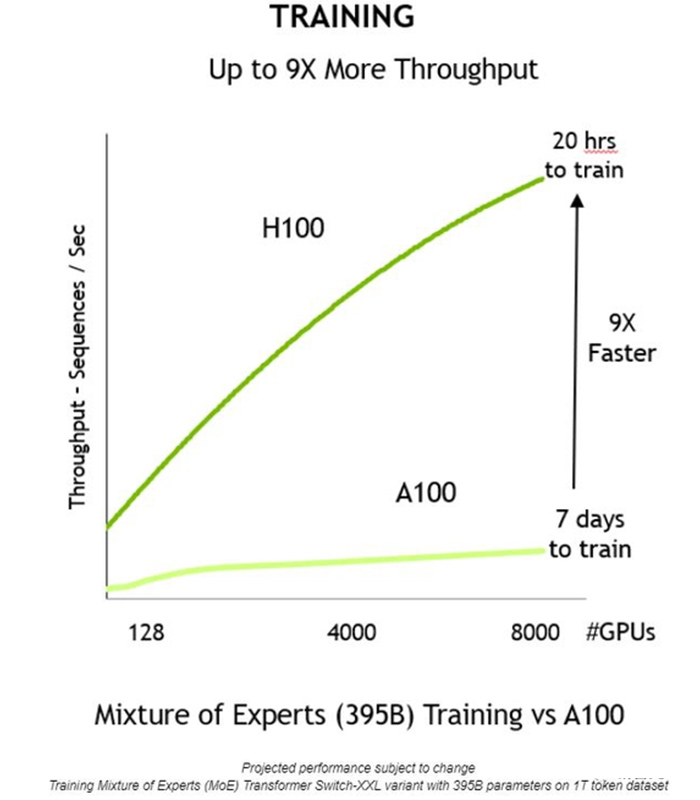 ▲ H100訓練MoE
▲ H100訓練MoE
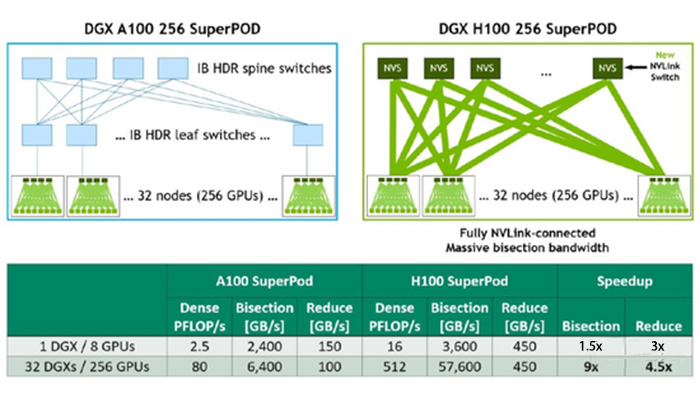 ▲ H100大規模加速
▲ H100大規模加速
大多數公司購買H100,並將其用於訓練和推理,而A100主要用於推理。但是,由於成本、容量、使用新硬體和設定新硬體的風險,以及現有的軟體已經針對A100進行了最佳化,有些公司會猶豫是否要切換。
GPU 並不短缺,而是供應鏈問題NVIDIA的一位高層表示,問題不在於 GPU 短缺,而在於這些 GPU 如何進入市場。
NVIDIA正在正在開足馬力生產GPU,但是這位高層稱,GPU的產能最主要受到的是供應鏈的限制。
晶片本身可能產能充足,但是其他的元件的產能不足會嚴重限制GPU的產能。
這些元件的生產要依賴整個世界範圍內的其他供應商。
不過需求是可以預測的,所以現在問題正在逐漸得到解決。
GPU晶片的產能情況首先,NVIDIA只與台積電合作生產H100。NVIDIA所有的5nmGPU都只與台積電合作。

未來可能會與英特爾和三星合作,但是短期內不可能,這就使得H100的生產受到了限制。
根據爆料者稱,台積電有4個生產節點為5nm晶片提供產能:N5、N5P、N4、N5P
H100隻在N5或者是N5P的中的4N節點上生產,是一個5nm的增強型節點。而NVIDIA需要和蘋果、高通和AMD共享這個節點的產能。台積電晶圓廠則需要提前12個月就對各個客戶的產能搭配做出規劃,如果之前NVIDIA和台積電低估了H100的需求,那麼現在產能就會受到限制。
爆料者稱,H100到從生產到出廠大約需要半年的時間,而且爆料者還引用某位退休的半導體行業專業人士的說法,晶圓廠並不是台積電的生產瓶頸,CoWoS(3D堆疊)封裝才是台積電的產能大門。
H100記憶體產能而對於H100上的另一個重要元件,H100記憶體,也可能存在產能不足的問題。
與GPU以一種特殊方式內建的HBM(High Bandwidth Memory)是保障GPU性能的關鍵元件。
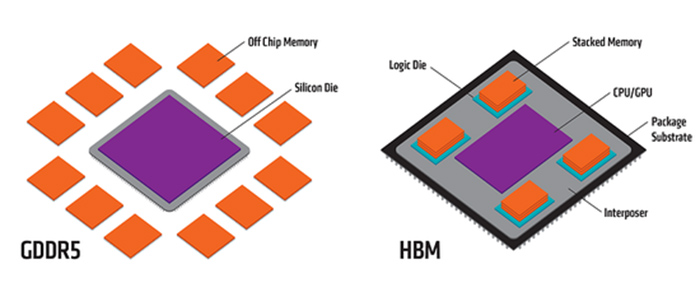
爆料者援引一位業內人士的說法:「主要的問題是 HBM。製造它是一場噩夢。由於 HBM 很難生產,供應也非常有限。生產和設計都必須按照它的節奏來。」
HBM3記憶體,NVIDIA幾乎都是採用SK Hynix的產品,可能會有一部分三星的產品,應該沒有鎂光的產品。NVIDIA希望SK Hynix能提高產能,他們也在這麼做。但是三星和鎂光的產能都很有限。而且製造GPU還會用到包括稀土元素在內的許多其他材料和工藝,也會成為限制GPU產能的可能因素。
GPU晶片未來的情況會怎麼發展NVIDIA首席財務官 Colette Kress 在2023年2月至4月的財報電話會議上透露:「下半年他們能夠供應更多的GPU,但是沒有提供任何定量的資訊。我們今天正在處理本季度的供應,但我們也為下半年採購了大量供應。我們相信下半年的供應量將大大高於上半年。」
某私有雲負責人透露,GPU的供應問題現在是一個惡性循環,稀缺性導致GPU擁有量被視為護城河,從而導致更多的GPU被囤積起來,從而加劇稀缺性。
根據NVIDIA之前的線路圖,H100的下一代產品要在2024年末到2025年初才會宣佈。在那個時間點之前,H100都會是NVIDIA的旗艦產品,不過NVIDIA在此期間內會推出120GB水冷版的H100。
而根據爆料者採訪到的業內人士稱,到2023年底的H100都已經賣完了!!
就像前面NVIDIA的高層提到的,H100的GPU所提供的算力,最終要通過各個雲端運算提供商整合到產業鏈中去,所以H100的短缺,一方面是GPU生成造成的。另一個方面,是算力雲提供商怎麼能有效地從NVIDIA獲得H100,並通過提供雲算力最終觸及需要的客戶。
這個過程簡單來說是:
算力雲提供商向OEM採購H100晶片,再搭建算力雲服務出售給各個AI企業,使得最終的使用者能夠獲得H100的算力。而這個過程中同樣存在各種因素,造成了目前H100算力的短缺,而爆料的文章也提供了很多行業內部的資訊供大家參考。
H100的板卡找誰買?戴爾,聯想,HPE,Supermicro和廣達等OEM商家都會銷售H100和HGX H100。
像CoreWeave和Lambda這樣的GPU雲提供商從OEM廠家處購買,然後租給初創公司。超大規模的企業(Azure、GCP、AWS、Oracle)會更直接與NVIDIA合作,但也會向OEM處購買。這和遊戲玩家買顯示卡的管道似乎也差不多。但即使是購買DGX,使用者也需要通過OEM購買,不能直接向NVIDIA下訂單。
交貨時間:
8-GPU HGX 伺服器的交付時間很糟糕,4-GPU HGX 伺服器的交付時間就還好。
但是每個客戶都想要 8-GPU 伺服器!
初創公司是否從原始裝置製造商和經銷商處購買產品?初創公司如果要獲得H100的算力,最終不是自己買了H100插到自己的GPU叢集中去。
他們通常會向Oracle等大型雲租用算力,或者向Lambda和CoreWeave等私有雲租用,或者向與OEM和資料中心合作的提供商(例如 FluidStack)租用。

如果想要自己建構資料中心,需要考慮的是建構資料中心的時間、是否有硬體方面的人員和經驗以及資本支出是否能夠承擔。
某私有雲負責人:「租用和託管伺服器已經變得更加容易了。如果使用者想建立自己的資料中心,必須佈置一條暗光纖線路才能連接到Internet - 每公里 1 萬美元。大部分基礎設施已經在Internet繁榮時期建成並支付了費用。租就行了,很便宜。」
從租賃到自建雲服務的順序大概是:按需租雲服務(純租賃雲服務)、預定雲服務、託管雲服務(購買伺服器,與提供商合作託管和管理伺服器)、自託管(自己購買和託管伺服器))。
大部分需要H100算力的初創公司都會選擇預定雲服務或者是託管雲服務。
大型雲端運算平台之間的比較而對於很多初創公司而言,大型雲端運算公司提供的雲服務,才是他們獲得H100的最終來源。雲平台的選擇也最終決定了他們能否獲得穩定的H100算力。
總體的觀點是:Oracle 不如三大雲可靠。但是Oracle會提供更多的技術支援幫助。
其他幾家大型雲端運算公司的主要差異在於:網路:儘管大多數尋求大型 A100/H100 叢集的初創公司都在尋求InfiniBand,AWS 和 Google Cloud 採用InfiniBand的速度較慢,因為它們用了自己的方法來提供服務。
可用性:微軟Azure的H100大部分都是專供OpenAI的。Google獲取H100比較困難。

因為NVIDIA似乎傾向於為那些沒有計畫開發和他競爭的機器學習晶片的雲提供更多的H100配額。(這都是猜測,不是確鑿的事實。)
而除了微軟外的三大雲公司都在開發機器學習晶片,來自AWS和Google的NVIDIA替代產品已經上市了,佔據了一部分市佔率。
就與NVIDIA的關係而言,可能是這樣的:Oracle和Azure>GCP和AWS。但這只是猜測。
較小的雲算力提供商價格會更便宜,但在某些情況下,一些雲端運算提供商會用算力去換股權。
NVIDIA如何分配H100NVIDIA會為每個客戶提供了H100的配額。
但如果Azure說「嘿,我們希望獲得10,000個H100,全部給Inflection使用」會與Azure說「嘿,我們希望獲得10,000個H100用於Azure雲」得到不同的配額。
NVIDIA關心最終客戶是誰,因此如果NVIDIA如果對最終的使用客戶感興趣的話,雲端運算提供平台就會得到更多的H100。
NVIDIA希望儘可能地瞭解最終客戶是誰,他們更喜歡擁有好品牌的客戶或擁有強大血統的初創公司。
某私有雲負責人透露,NVIDIA 喜歡保證新興人工智慧公司(其中許多公司與他們有密切的關係)能夠使用 GPU。請參閱 Inflection—他們投資的一家人工智慧公司,在他們也投資的 CoreWeave 上測試一個巨大的 H100 叢集。
現在對於GPU的渴求既有泡沫和炒作的成分,但是也確實是客觀存在的。
OpenAI 等一些公司推出了ChatGPT等產品,這些產品收到了市場的追捧,但他們依然無法獲得足夠的GPU。
其他公司正在購買並且囤積GPU,以便將來能夠使用,或者用來訓練一些市場可能根本用不到的大語言模型。這就產生了GPU短缺的泡沫。
但無論你怎麼看,NVIDIA就是堡壘中的國王。

加入T客邦Facebook粉絲團 固定链接 'AI進化太慢怪老黃?全球各大公司H100晶片總需求估43萬張,NVIDIA GPU不夠真是老黃產能的問題?' 提交: August 8, 2023, 10:30pm CST