
еңЁзңӢе®ҢдәҶGeForce RTX 4090зҡ„ж•ҲиғҪжё¬и©ҰеҫҢпјҢжҺҘи‘—жҲ‘еҖ‘е°ұз№јзәҢдҫҶеҲҶжһҗе…Ёж–°зҡ„Ada Lovelaceз№Әең–жһ¶ж§ӢпјҢж·ұе…Ҙзһӯи§Је…¶ж”№йҖІд№Ӣиҷ•гҖӮ
йҒӢз®—жһ¶ж§Ӣзө„жҲҗйҰ–е…ҲжҲ‘еҖ‘д»ҘGeForce RTX 4090зҡ„AD102 GPUдҫҶиӘӘжҳҺAda Lovelaceз№Әең–жһ¶ж§Ӣзҡ„йҒӢз®—е–®е…ғзө„жҲҗж–№ејҸгҖӮ
е®Ңж•ҙзҡ„AD102е…·жңү12зө„ең–еғҸиҷ•зҗҶеҸўйӣҶпјҲGraphics Processing ClustersпјҢGPCпјүгҖҒ72зө„жқҗиіӘиҷ•зҗҶеҸўйӣҶпјҲTexture Processing ClustersпјҢTPCпјүгҖҒ144зө„дёІжөҒеӨҡйҮҚиҷ•зҗҶеҷЁпјҲStreaming MultiprocessorsпјҢSMпјүпјҢзёҪе…ұжңү18432зө„CUDAж ёеҝғгҖӮиҮіж–јиЁҳжҶ¶й«”йғЁеҲҶпјҢеүҮжҳҜз”ұ12зө„еҜ¬еәҰзӮә32bitзҡ„жҺ§еҲ¶еҷЁзө„жҲҗзёҪеҜ¬еәҰзӮә384bitзҡ„иЁҳжҶ¶й«”йҖҡйҒ“пјҢжӯӨеӨ–йӮ„жңүзҚЁз«Ӣзҡ„е…үжөҒеҠ йҖҹеҷЁпјҲOptical Flow AcceleratorпјүпјҢд»ҘеҸҠNVENCз·ЁзўјеҷЁгҖҒNVDECи§ЈзўјеҷЁеҗ„3зө„пјҢдёҰйҖҸйҒҺPCIe Gen 4x16еҢҜжөҒжҺ’йҖЈжҺҘиҮідё»ж©ҹжқҝгҖӮ
NVIDIAд№ҹеңЁAda LovelaceзҷҪзҡ®жӣёдёӯжҸҗеҲ°пјҢжҜҸзө„SMдёӯе…·жңү2еҖӢFP64йҒӢз®—ж ёеҝғпјҲзёҪйҮҸзӮә288еҖӢпјүпјҢз”ұж–јFP64иіҮж–ҷж јејҸзЁӢејҸзҡ„еҹ·иЎҢж•ҲзҺҮеғ…жңүFP32зҡ„1/64пјҢеӣ жӯӨйҖҷдәӣе°‘йҮҸзҡ„FP64йҒӢз®—ж ёеҝғзӣ®зҡ„еғ…зӮәзўәдҝқFP64зЁӢејҸиғҪеӨ жӯЈеёёйҒӢдҪңгҖӮ
иҲҮеүҚд»Јжһ¶ж§ӢзӣёжҜ”пјҢAda Lovelaceзҡ„SMе…·жңү2еҖҚзҡ„йҒӢз®—ж•ҲиғҪиҲҮйӣ»еҠӣж•ҲзҺҮпјҢеӣ жӯӨиғҪеңЁдёҚеўһеҠ йӣ»еҠӣж¶ҲиҖ—зҡ„еүҚжҸҗдёӢпјҢйҒ”еҲ°зӣёеҗҢж•ҲиғҪијёеҮәпјҢжҲ–жҳҜеңЁж¶ҲиҖ—зӣёеҗҢйӣ»еҠӣзҡ„жғ…жіҒдёӢпјҢе°Үж•ҲиғҪијёеҮәжҸҗеҚҮ2еҖҚгҖӮ
иҖҢеҜҰйҡӣжҗӯијүж–јGeForce RTX 4090зҡ„AD102еүҮеұҸи”Ҫ1зө„GPCпјҢеӣ жӯӨзёҪе…ұе°‘дәҶ6зө„TPCгҖҒ12зө„SMгҖҒ1536зө„CUDAж ёеҝғпјҢи©ізҙ°иҰҸж ји«ӢеҸғиҖғдёӢиЎЁгҖӮжӯӨеӨ–GeForce RTX 4090д№ҹеғ…дҝқз•ҷ2зө„NVENCз·ЁзўјеҷЁиҲҮ1зө„NVDECи§ЈзўјеҷЁпјҢдҪҶиЁҳжҶ¶й«”жҺ§еҲ¶еҷЁиҲҮе…үжөҒеҠ йҖҹеҷЁеүҮз„Ўз•°еӢ•гҖӮ
пјҲиӢҘжүӢж©ҹзүҲзҖҸиҰҪеҷЁз„Ўжі•йЎҜзӨәиЎЁж јпјҢи«Ӣй»һжҲ‘зңӢе®Ңж•ҙиЎЁж јпјү
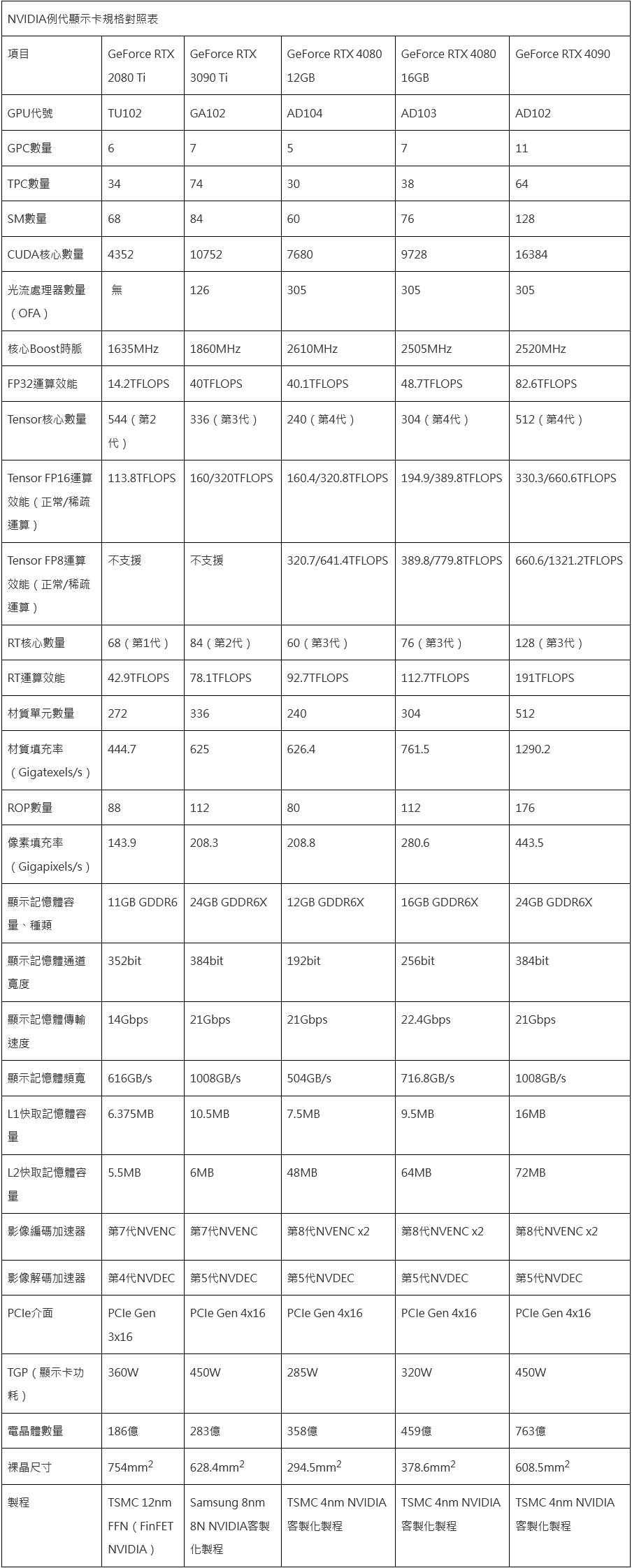{kind=link}
| NVIDIAдҫӢд»ЈйЎҜзӨәеҚЎиҰҸж је°Қз…§иЎЁ | |||||
| й …зӣ® | GeForce RTX 2080 Ti | GeForce RTX 3090 Ti | GeForce RTX 4080 12GB | GeForce RTX 4080 16GB | GeForce RTX 4090 |
| GPUд»Јиҷҹ | TU102 | GA102 | AD104 | AD103 | AD102 |
| GPCж•ёйҮҸ | 6 | 7 | 5 | 7 | 11 |
| TPCж•ёйҮҸ | 34 | 74 | 30 | 38 | 64 |
| SMж•ёйҮҸ | 68 | 84 | 60 | 76 | 128 |
| CUDAж ёеҝғж•ёйҮҸ | 4352 | 10752 | 7680 | 9728 | 16384 |
| е…үжөҒиҷ•зҗҶеҷЁж•ёйҮҸпјҲOFAпјү | В з„Ў | 126 | 305 | 305 | 305 |
| ж ёеҝғBoostжҷӮи„Ҳ | 1635MHz | 1860MHz | 2610MHz | 2505MHz | 2520MHz |
| FP32йҒӢз®—ж•ҲиғҪ | 14.2TFLOPS | 40TFLOPS | 40.1TFLOPS | 48.7TFLOPS | 82.6TFLOPS |
| Tensorж ёеҝғж•ёйҮҸ | 544пјҲ第2д»Јпјү | 336пјҲ第3д»Јпјү | 240пјҲ第4д»Јпјү | 304пјҲ第4д»Јпјү | 512пјҲ第4д»Јпјү |
| Tensor FP16йҒӢз®—ж•ҲиғҪпјҲжӯЈеёё/зЁҖз–ҸйҒӢз®—пјү | 113.8TFLOPS | 160/320TFLOPS | 160.4/320.8TFLOPS | 194.9/389.8TFLOPS | 330.3/660.6TFLOPS |
| Tensor FP8йҒӢз®—ж•ҲиғҪпјҲжӯЈеёё/зЁҖз–ҸйҒӢз®—пјү | дёҚж”ҜжҸҙ | дёҚж”ҜжҸҙ | 320.7/641.4TFLOPS | 389.8/779.8TFLOPS | 660.6/1321.2TFLOPS |
| RTж ёеҝғж•ёйҮҸ | 68пјҲ第1д»Јпјү | 84пјҲ第2д»Јпјү | 60пјҲ第3д»Јпјү | 76пјҲ第3д»Јпјү | 128пјҲ第3д»Јпјү |
| RTйҒӢз®—ж•ҲиғҪ | 42.9TFLOPS | 78.1TFLOPS | 92.7TFLOPS | 112.7TFLOPS | 191TFLOPS |
| жқҗиіӘе–®е…ғж•ёйҮҸ | 272 | 336 | 240 | 304 | 512 |
| жқҗиіӘеЎ«е……зҺҮпјҲGigatexels/sпјү | 444.7 | 625 | 626.4 | 761.5 | 1290.2 |
| ROPж•ёйҮҸ | 88 | 112 | 80 | 112 | 176 |
| еғҸзҙ еЎ«е……зҺҮпјҲGigapixels/sпјү | 143.9 | 208.3 | 208.8 | 280.6 | 443.5 |
| йЎҜзӨәиЁҳжҶ¶й«”е®№йҮҸгҖҒзЁ®йЎһ | 11GB GDDR6 | 24GB GDDR6X | 12GB GDDR6X | 16GB GDDR6X | 24GB GDDR6X |
| йЎҜзӨәиЁҳжҶ¶й«”йҖҡйҒ“еҜ¬еәҰ | 352bit | 384bit | 192bit | 256bit | 384bit |
| йЎҜзӨәиЁҳжҶ¶й«”еӮіијёйҖҹеәҰ | 14Gbps | 21Gbps | 21Gbps | 22.4Gbps | 21Gbps |
| йЎҜзӨәиЁҳжҶ¶й«”й »еҜ¬ | 616GB/s | 1008GB/s | 504GB/s | 716.8GB/s | 1008GB/s |
| L1еҝ«еҸ–иЁҳжҶ¶й«”е®№йҮҸ | 6.375MB | 10.5MB | 7.5MB | 9.5MB | 16MB |
| L2еҝ«еҸ–иЁҳжҶ¶й«”е®№йҮҸ | 5.5MB | 6MB | 48MB | 64MB | 72MB |
| еҪұеғҸз·ЁзўјеҠ йҖҹеҷЁ | 第7д»ЈNVENC | 第7д»ЈNVENC | 第8д»ЈNVENC x2 | 第8д»ЈNVENC x2 |
第8代NVENC x2 |
| еҪұеғҸи§ЈзўјеҠ йҖҹеҷЁ | 第4д»ЈNVDEC | 第5д»ЈNVDEC | 第5д»ЈNVDEC | 第5д»ЈNVDEC | 第5д»ЈNVDEC |
| PCIeд»Ӣйқў | PCIe Gen 3x16 | PCIe Gen 4x16 | PCIe Gen 4x16 | PCIe Gen 4x16 | PCIe Gen 4x16 |
| TGPпјҲйЎҜзӨәеҚЎеҠҹиҖ—пјү | 360W | 450W | 285W | 320W | 450W |
| йӣ»жҷ¶й«”ж•ёйҮҸ | 186е„„ | 283е„„ | 358е„„ | 459е„„ | 763е„„ |
| иЈёжҷ¶е°әеҜё | 754mm2 | 628.4mm2 | 294.5mm2 | 378.6mm2 | 608.5mm2 |
| иЈҪзЁӢ | TSMC 12nm FFNпјҲFinFET NVIDIAпјү | Samsung 8nm 8N NVIDIAе®ўиЈҪеҢ–иЈҪзЁӢ | TSMC 4nm NVIDIAе®ўиЈҪеҢ–иЈҪзЁӢ | TSMC 4nm NVIDIAе®ўиЈҪеҢ–иЈҪзЁӢ | TSMC 4nm NVIDIAе®ўиЈҪеҢ–иЈҪзЁӢ |
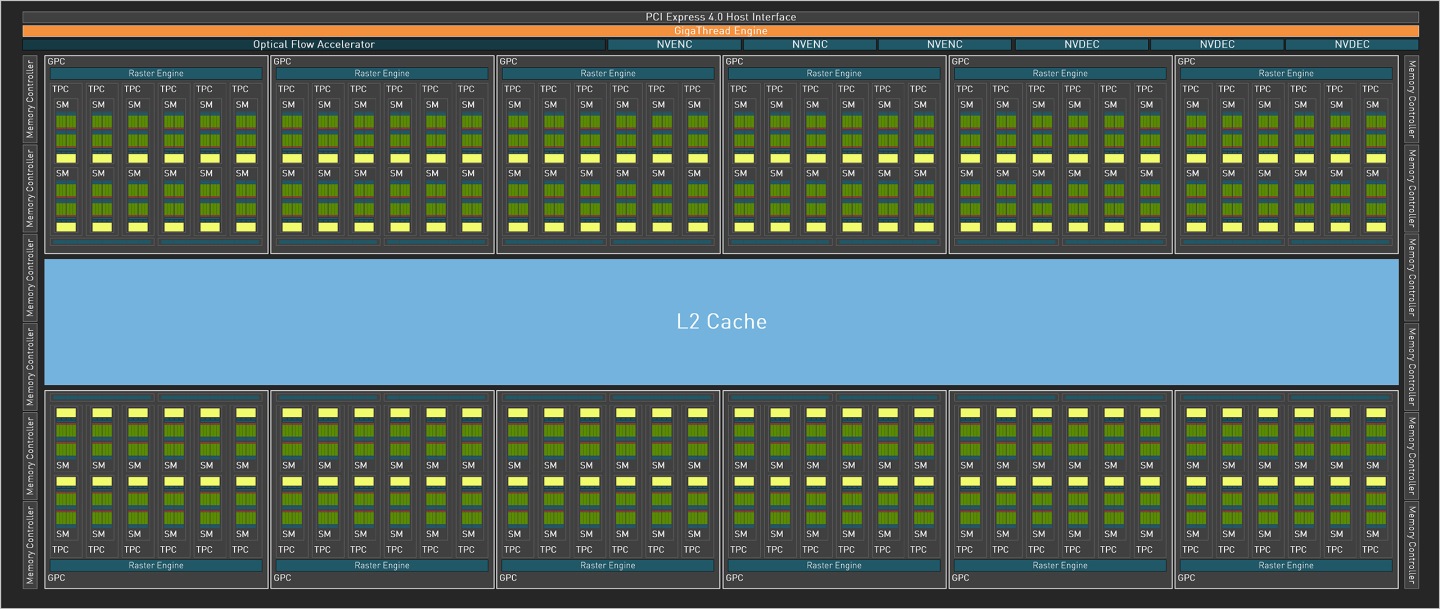 в–І е®Ңж•ҙзҡ„AD102е…·жңү12зө„GPCпјҢд»ҘеҸҠNVENCз·ЁзўјеҷЁгҖҒNVDECи§ЈзўјеҷЁеҗ„2зө„гҖӮ
в–І е®Ңж•ҙзҡ„AD102е…·жңү12зө„GPCпјҢд»ҘеҸҠNVENCз·ЁзўјеҷЁгҖҒNVDECи§ЈзўјеҷЁеҗ„2зө„гҖӮ
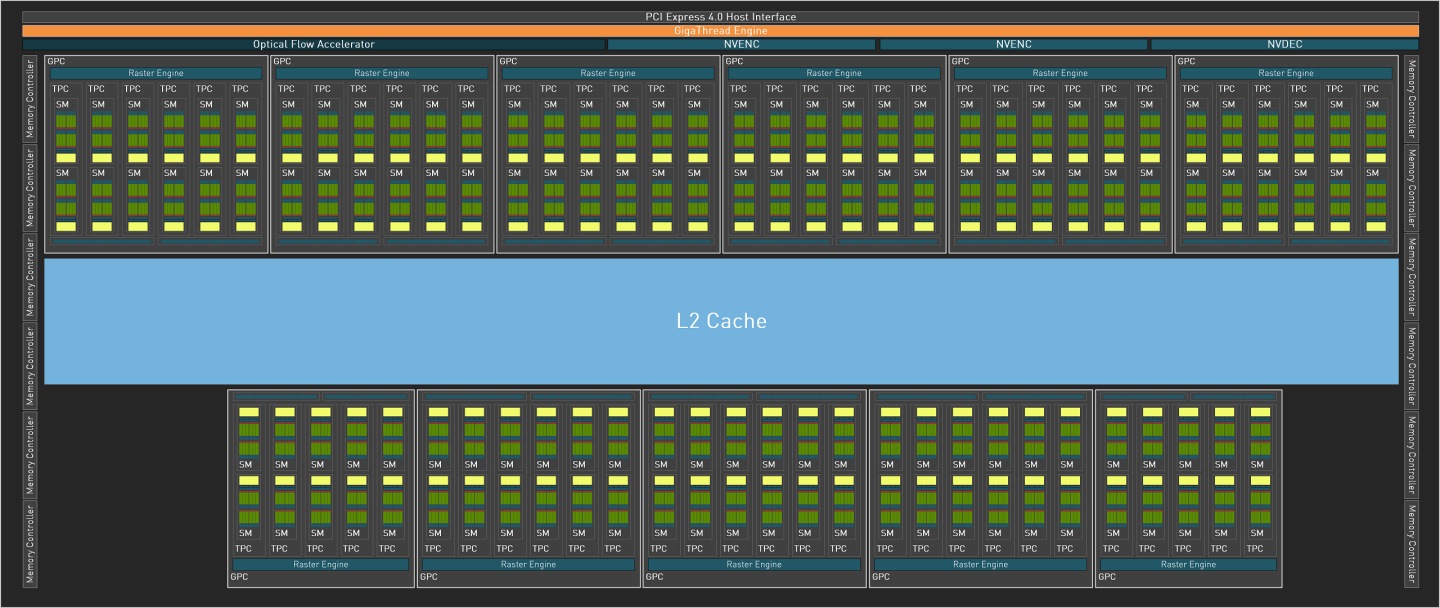 в–І GeForce RTX 4090зҡ„AD102еүҮеұҸи”ҪйғЁеҲҶе…ғ件пјҢи®ҠжҲҗеҸӘжңү11зө„GPCпјҢд№ҹеғ…дҝқз•ҷ2зө„NVENCз·ЁзўјеҷЁиҲҮ1зө„NVDECи§ЈзўјеҷЁгҖӮ
в–І GeForce RTX 4090зҡ„AD102еүҮеұҸи”ҪйғЁеҲҶе…ғ件пјҢи®ҠжҲҗеҸӘжңү11зө„GPCпјҢд№ҹеғ…дҝқз•ҷ2зө„NVENCз·ЁзўјеҷЁиҲҮ1зө„NVDECи§ЈзўјеҷЁгҖӮ
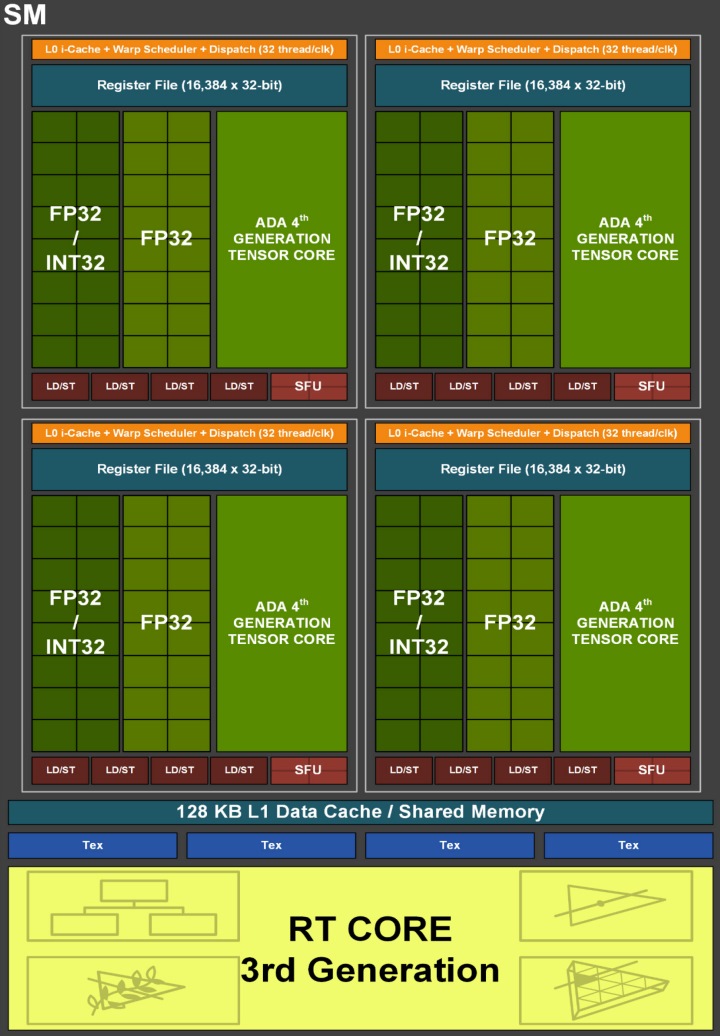 в–І SMзҡ„зҙ°йғЁзө„жҲҗеҰӮең–жүҖзӨәгҖӮйңҖиҰҒжіЁж„Ҹзҡ„жҳҜж–ҮдёӯжҸҗеҲ°зҡ„FP64йҒӢз®—ж ёеҝғдёҰжңӘз№ӘиЈҪж–јең–дёӯгҖӮ
в–І SMзҡ„зҙ°йғЁзө„жҲҗеҰӮең–жүҖзӨәгҖӮйңҖиҰҒжіЁж„Ҹзҡ„жҳҜж–ҮдёӯжҸҗеҲ°зҡ„FP64йҒӢз®—ж ёеҝғдёҰжңӘз№ӘиЈҪж–јең–дёӯгҖӮ
 в–І еңЁи»ҹй«”ж”ҜжҸҙзҡ„жғ…жіҒдёӢпјҢGeForce RTX 4090зҡ„2зө„NVENCз·ЁзўјеҷЁеҸҜд»ҘеҗҢжҷӮйҒӢдҪңпјҢйҖІиЎҢеҚіжҷӮ8Kз·ЁзўјиҪүжӘ”гҖӮ
в–І еңЁи»ҹй«”ж”ҜжҸҙзҡ„жғ…жіҒдёӢпјҢGeForce RTX 4090зҡ„2зө„NVENCз·ЁзўјеҷЁеҸҜд»ҘеҗҢжҷӮйҒӢдҪңпјҢйҖІиЎҢеҚіжҷӮ8Kз·ЁзўјиҪүжӘ”гҖӮ
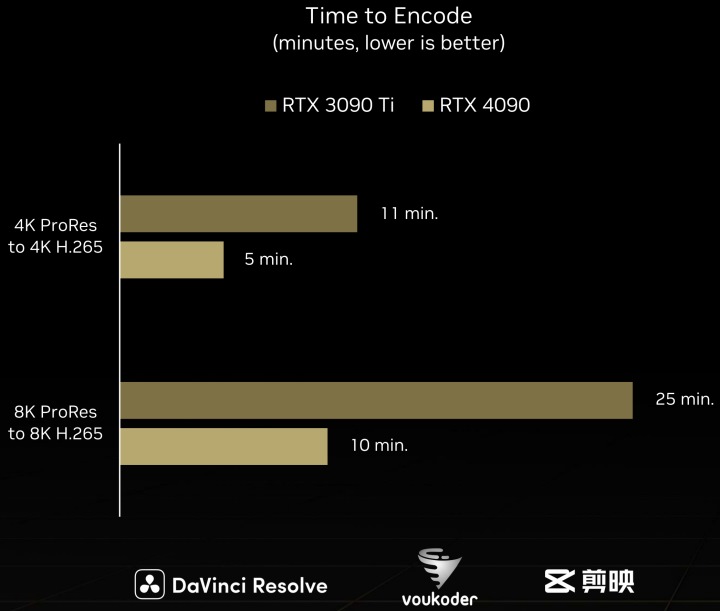 в–І ж №ж“ҡе®ҳж–№жҸҗдҫӣзҡ„жё¬и©Ұж•ёж“ҡпјҢGeForce RTX 4090зҡ„з·ЁзўјйҖҹеәҰжҜ”GeForce RTX 3090 Tiй«ҳеҮә1еҖҚд»ҘдёҠгҖӮ
в–І ж №ж“ҡе®ҳж–№жҸҗдҫӣзҡ„жё¬и©Ұж•ёж“ҡпјҢGeForce RTX 4090зҡ„з·ЁзўјйҖҹеәҰжҜ”GeForce RTX 3090 Tiй«ҳеҮә1еҖҚд»ҘдёҠгҖӮ
пјҲдёӢй ҒйӮ„жңүе…үз·ҡиҝҪи№Өж•ҲиғҪжҸҗеҚҮзҡ„и§ЈиӘӘпјү
е…үз·ҡиҝҪи№ӨеҶҚеҠ йҖҹRTX 20иҲҮRTX 30дё–д»Јзҡ„TuringгҖҒAmpereз№Әең–жһ¶ж§Ӣе…·жңүеҠ йҖҹBVHпјҲBounding Volume HierarchyпјҢеҒөжё¬е…үз·ҡжҳҜеҗҰжңүгҖҢзў°ж’һгҖҚеҲ°зү©й«”пјүзҡ„Box Intersection EngineйҒӢз®—е–®е…ғпјҢд»ҘеҸҠеҠ йҖҹеӨҡйӮҠеһӢиҲҮе…үз·ҡйӮҠжЎҶзӣёдәӨжё¬и©Ұзҡ„Triangle Intersection EngineйҒӢз®—е–®е…ғпјҢиғҪеӨ жңүж•ҲеҚ”еҠ©йҷҚдҪҺSMзҡ„йҒӢз®—иІ ијүпјҢи®“SMиғҪеҹ·иЎҢжӣҙеӨҡеӮізөұзҡ„й Ӯй»һгҖҒеғҸзҙ йҒӢз®—гҖӮ
RTX 40дё–д»Јзҡ„Ada Lovelaceз№Әең–жһ¶ж§ӢйҷӨдәҶдҝқз•ҷйҖҷ2зЁ®йҒӢз®—е–®е…ғд№ӢеӨ–пјҢйӮ„е°Үе…үз·ҡеӨҡйӮҠеҪўдәӨжңғпјҲRay-Triangle Intersectionпјүзҡ„йҒӢз®—еҗһеҗҗйҮҸжҸҗеҚҮпј’еҖҚпјҢдёҰеҠ е…ҘдәҶеҸҜд»ҘжҸҗдҫӣйҖҸжҳҺиІјең–е…үз·ҡеҒөжё¬йҖҹеәҰпј’еҖҚзҡ„йҖҸжҳҺиҝ·дҪ иІјең–еј•ж“ҺпјҲOpacity Micromap EngineпјүпјҢд»ҘеҸҠиғҪеӨ жҘөеӨ§е№…жҸҗеҚҮBVHе»әж§ӢйҖҹеәҰиҲҮйҷҚдҪҺдҪ”з”Ёе®№йҮҸзҡ„иҝ·дҪ з¶Іж јдҪҚ移引ж“ҺпјҲDisplaced Micro-Mesh EngineпјүгҖӮ
йҰ–е…ҲжҲ‘еҖ‘е…ҲдҫҶзһӯи§ЈйҖҸжҳҺиҝ·дҪ иІјең–еј•ж“Һзҡ„жҰӮеҝөгҖӮиЁұеӨҡйҒҠжҲІй–ӢзҷјиҖ…жңғеҲ©з”ЁжқҗиіӘиІјең–зҡ„AlphaйҖҡйҒ“пјҲйҖҸжҳҺеәҰпјүдҫҶзһ„з№ӘиӨҮйӣңзҡ„еҪўзӢҖжҲ–еҚҠйҖҸжҳҺзү©е“ҒпјҢиҲүдҫӢдҫҶиӘӘжЁ№и‘үжҲ–зҒ«зҮ„зӯүиӨҮйӣңеҪўзӢҖеҸҜд»ҘйҖҸйҒҺе°‘йҮҸеӨҡйӮҠеҪўжҗӯй…ҚAlphaйҖҡйҒ“е®ҢжҲҗжҸҸз№ӘпјҢдёҰзҜҖзңҒиЁұеӨҡеӮізөұз№Әең–зҡ„йҒӢз®—йңҖжұӮгҖӮдёҚйҒҺеңЁе…үз·ҡиҝҪи№Өз№Әең–зҡ„жғ…жіҒпјҢзі»зөұе°ұйңҖиҰҒеҒөжё¬жҜҸйҒ“е…үз·ҡжҳҜеҗҰжңғгҖҢз©ҝйҖҸгҖҚиІјең–пјҢиҖҢж¶ҲиҖ—еӨ§йҮҸйҒӢз®—иіҮжәҗгҖӮ
еңЁAda Lovelaceе°Һе…Ҙзҡ„йҖҸжҳҺиҝ·дҪ иІјең–еј•ж“ҺпјҢжңғе°ҮиІјең–еҲҮеҲҶзӮәиЁұеӨҡзҙ°е°Ҹзҡ„иҷӣж“¬з¶Іж јпјҢдёҰиЁҳйҢ„еҸҜдҫӣRTж ёеҝғзӣҙжҺҘжҹҘи©ўзҡ„йҖҸжҳҺеәҰзӢҖж…ӢпјҢиӢҘе…үз·ҡзў°еҲ°жЁҷиЁҳзӮәгҖҢдёҚйҖҸжҳҺгҖҚзҡ„еҚҖеҹҹеүҮжңғеӣһеӮіе…үз·ҡзў°ж’һзҡ„зөҗжһңпјҢиӢҘзў°еҲ°гҖҢйҖҸжҳҺгҖҚеҚҖеҹҹеүҮжңғи®“е…үз·ҡз№јзәҢеүҚйҖІдёҰжүҫе°ӢдёӢдёҖеҖӢзў°ж’һй»һгҖӮеҰӮжһңзў°еҲ°гҖҢжңӘзҹҘгҖҚеҚҖеҹҹпјҢзі»зөұжүҚжңғе°ҮйҒӢз®—иІ ијүдәӨйӮ„зөҰSMдёҰйҒӢз®—зў°ж’һзӢҖжіҒпјҢеҰӮжӯӨдёҖдҫҶдҫҝеҸҜзңҒдёӢеҸҜи§Җзҡ„йҒӢз®—йҮҸгҖӮ
иҝ·дҪ з¶Іж јдҪҚ移引ж“ҺеүҮжҳҜеҸҜд»Ҙи§Јжұәз”Ёж–јжҸҸз№Әзү©д»¶зҡ„еӨҡйӮҠеҪўж•ёйҮҸи¶ҠдҫҶи¶ҠеӨҡпјҢжүҖиЎҚз”ҹзҡ„BVHйҒӢз®—йҮҸиҲҮеҚ з”ЁиЁҳжҶ¶й«”з©әй–“е•ҸйЎҢгҖӮе…¶жҰӮеҝөзӮәдҪҝз”Ёе–®дёҖзҡ„еҹәжң¬дёүи§’еҪўпјҲBase Triangleпјүжҗӯй…ҚдҪҚ移жҳ е°„ең–пјҲDisplacement MapпјүпјҢдҫҶ模擬дҪҝз”ЁеӨ§йҮҸеӨҡйӮҠеһӢжүҖз№ӘиЈҪзҡ„зү©д»¶пјҢеҰӮжӯӨдёҖдҫҶдҫҝеҸҜз°ЎеҢ–е…үз·ҡзў°ж’һзҡ„еҒөжё¬жј”з®—пјҢйҷӨдәҶеҸҜд»ҘеӨ§е№…жҸҗеҚҮBVHзҡ„йҒӢз®—йҖҹеәҰпјҢйӮ„иғҪеӨ§йҮҸйҷҚдҪҺеҚ з”ЁиЁҳжҶ¶й«”з©әй–“пјҢйҖІиҖҢжҸҗеҚҮе…үз·ҡиҝҪи№Өзҡ„ж•ҙй«”йҒӢз®—ж•ҲиғҪгҖӮ
 в–І е–®зҙ”дҪҝз”ЁдёҚйҖҸжҳҺеӨҡйӮҠеҪўжҸҸз№ӘжЁ№и‘үжҲ–зҒ«зҮ„е°ҮжңғеҫҲиӨҮйӣңпјҢе°Һе…ҘAlphaйҖҡйҒ“е°ҮеҸҜеӨ§е№…з°ЎеҢ–з№ӘиЈҪе·ҘдҪңгҖӮ
в–І е–®зҙ”дҪҝз”ЁдёҚйҖҸжҳҺеӨҡйӮҠеҪўжҸҸз№ӘжЁ№и‘үжҲ–зҒ«зҮ„е°ҮжңғеҫҲиӨҮйӣңпјҢе°Һе…ҘAlphaйҖҡйҒ“е°ҮеҸҜеӨ§е№…з°ЎеҢ–з№ӘиЈҪе·ҘдҪңгҖӮ
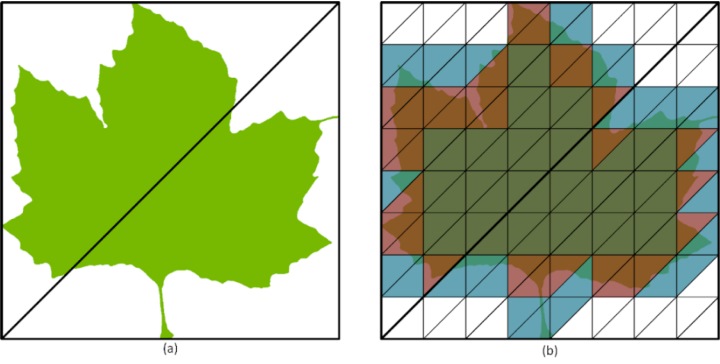 в–І еҸіең–зӮәйҖҸжҳҺиҝ·дҪ иІјең–зҡ„зӨәж„ҸпјҢз¶ иүІиҲҮзҷҪиүІеҚҖеҹҹеҲҶеҲҘзӮәгҖҢдёҚйҖҸжҳҺгҖҚиҲҮгҖҢйҖҸжҳҺгҖҚжЁҷиЁҳпјҢзҙ…иүІгҖҒи—ҚиүІеүҮзӮәгҖҢжңӘзҹҘгҖҚпјҢж•ҙй«”жңү41еҖӢдёҚйҖҸжҳҺгҖҒ30еҖӢйҖҸжҳҺгҖҒ57еҖӢжңӘзҹҘпјҢжңүжҠ„йҒҺдёҖеҚҠзҡ„еҚҖеҹҹзҡ„е…үз·ҡзў°ж’һзӢҖж…Ӣд»Ҙиў«жЁҷиЁҳгҖӮ
в–І еҸіең–зӮәйҖҸжҳҺиҝ·дҪ иІјең–зҡ„зӨәж„ҸпјҢз¶ иүІиҲҮзҷҪиүІеҚҖеҹҹеҲҶеҲҘзӮәгҖҢдёҚйҖҸжҳҺгҖҚиҲҮгҖҢйҖҸжҳҺгҖҚжЁҷиЁҳпјҢзҙ…иүІгҖҒи—ҚиүІеүҮзӮәгҖҢжңӘзҹҘгҖҚпјҢж•ҙй«”жңү41еҖӢдёҚйҖҸжҳҺгҖҒ30еҖӢйҖҸжҳҺгҖҒ57еҖӢжңӘзҹҘпјҢжңүжҠ„йҒҺдёҖеҚҠзҡ„еҚҖеҹҹзҡ„е…үз·ҡзў°ж’һзӢҖж…Ӣд»Ҙиў«жЁҷиЁҳгҖӮ
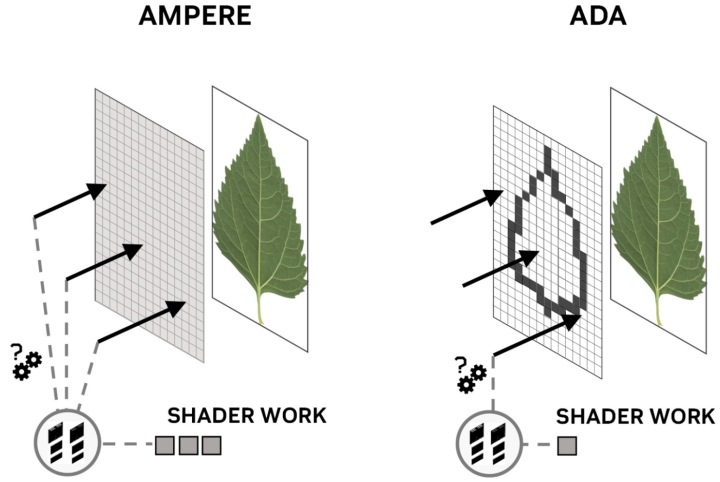 в–І е…ҲеүҚжһ¶ж§ӢйңҖиҰҒе°Қж•ҙејөжқҗиіӘиІјең–йҖІиЎҢе…үз·ҡзў°ж’һеҒөжё¬йҒӢз®—пјҢйҖҸжҳҺиҝ·дҪ иІјең–еј•ж“ҺеүҮеҸҜе°ҮйҒӢз®—йңҖжұӮйҷҚдҪҺеҲ°еҸӘеү©и‘үзүҮйӮҠз·ЈпјҢжңүж•ҲйҷҚдҪҺSMзҡ„е·ҘдҪңиІ ж“”гҖӮ
в–І е…ҲеүҚжһ¶ж§ӢйңҖиҰҒе°Қж•ҙејөжқҗиіӘиІјең–йҖІиЎҢе…үз·ҡзў°ж’һеҒөжё¬йҒӢз®—пјҢйҖҸжҳҺиҝ·дҪ иІјең–еј•ж“ҺеүҮеҸҜе°ҮйҒӢз®—йңҖжұӮйҷҚдҪҺеҲ°еҸӘеү©и‘үзүҮйӮҠз·ЈпјҢжңүж•ҲйҷҚдҪҺSMзҡ„е·ҘдҪңиІ ж“”гҖӮ
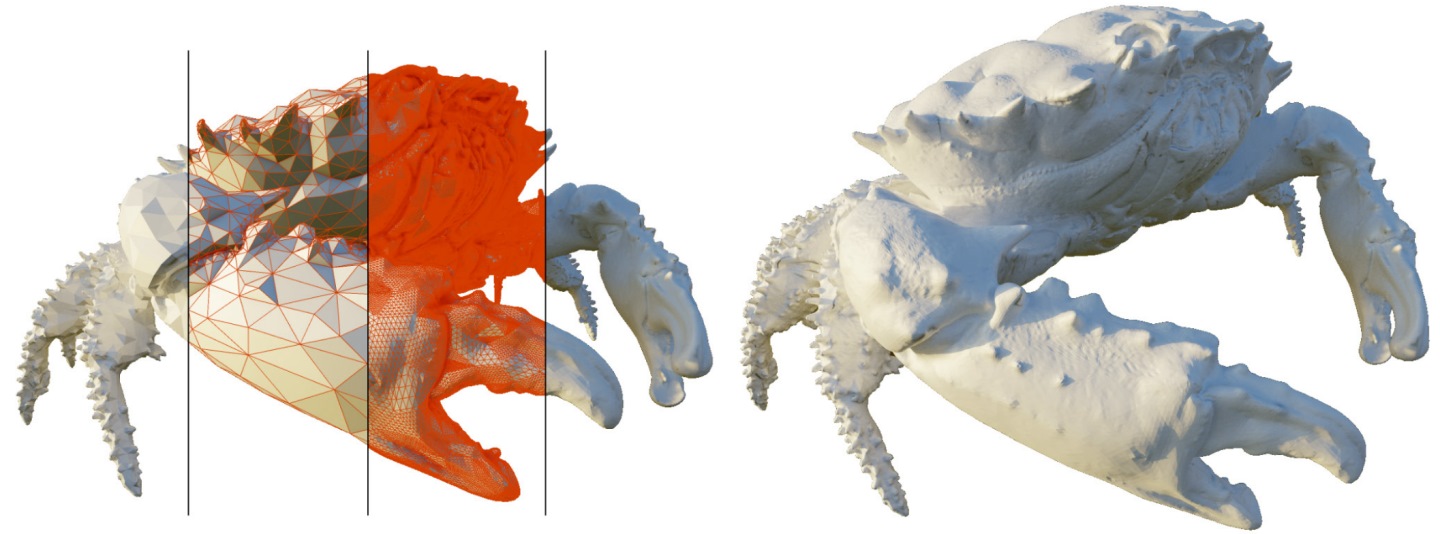 в–І еңЁиҝ·дҪ з¶Іж јдҪҚ移引ж“Һзҡ„зӨәж„ҸдёӯпјҢеҸҜд»ҘзңӢеҲ°е·Ұең–е·ҰеҒҙзҡ„зҙ…иүІдёүи§’еҪўеҚізӮәгҖҢеҹәжң¬дёүи§’еҪўгҖҚпјҢе·Ұең–еҸіеҒҙзӮәжҗӯй…ҚдҪҚ移жҳ е°„ең–иҖҢз”ўз”ҹзҡ„зҙ°иҶ©з¶Іж јгҖӮ
в–І еңЁиҝ·дҪ з¶Іж јдҪҚ移引ж“Һзҡ„зӨәж„ҸдёӯпјҢеҸҜд»ҘзңӢеҲ°е·Ұең–е·ҰеҒҙзҡ„зҙ…иүІдёүи§’еҪўеҚізӮәгҖҢеҹәжң¬дёүи§’еҪўгҖҚпјҢе·Ұең–еҸіеҒҙзӮәжҗӯй…ҚдҪҚ移жҳ е°„ең–иҖҢз”ўз”ҹзҡ„зҙ°иҶ©з¶Іж јгҖӮ
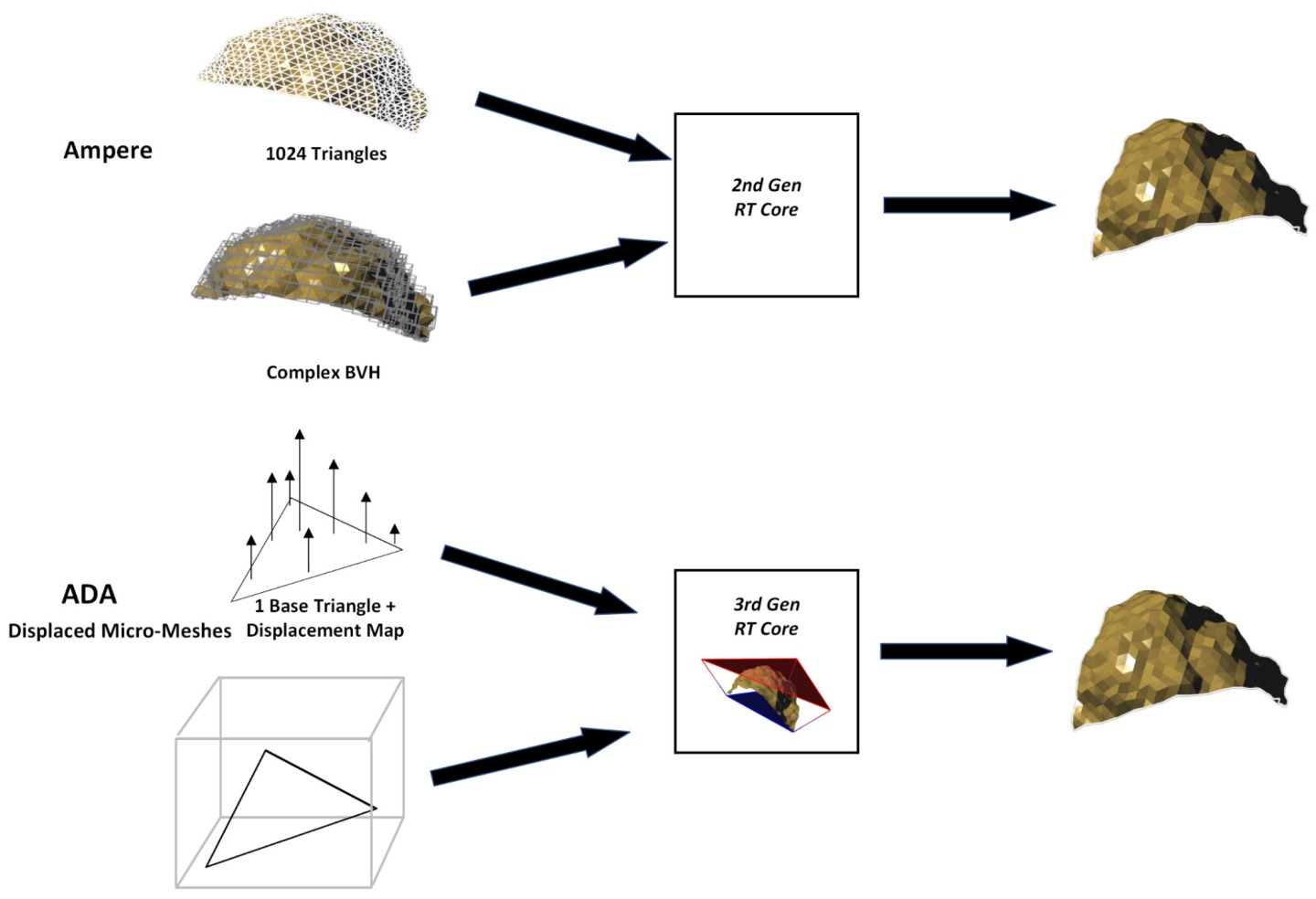 в–І 第3д»ЈRTж ёеҝғдҪҝз”Ёеҹәжң¬дёүи§’еҪўгҖҒдҪҚ移жҳ е°„ең–гҖҒз°Ўе–®BVHпјҲе·ҰдёӢпјүпјҢеҸ–д»Јй«ҳйҒ”1024еҖӢеӨҡйӮҠеҪўгҖҒиӨҮйӣңBVHпјҲе·ҰдёҠпјүпјҢијғе…ҲеүҚRTж ёеҝғж¶ҲиҖ—жӣҙе°‘иіҮжәҗдҫҝеҸҜе®ҢжҲҗйҒӢз®—гҖӮ
в–І 第3д»ЈRTж ёеҝғдҪҝз”Ёеҹәжң¬дёүи§’еҪўгҖҒдҪҚ移жҳ е°„ең–гҖҒз°Ўе–®BVHпјҲе·ҰдёӢпјүпјҢеҸ–д»Јй«ҳйҒ”1024еҖӢеӨҡйӮҠеҪўгҖҒиӨҮйӣңBVHпјҲе·ҰдёҠпјүпјҢијғе…ҲеүҚRTж ёеҝғж¶ҲиҖ—жӣҙе°‘иіҮжәҗдҫҝеҸҜе®ҢжҲҗйҒӢз®—гҖӮ
 в–І ж №ж“ҡNVIDIAе®ҳж–№жҸҗдҫӣзҡ„жЎҲдҫӢпјҢиҝ·дҪ з¶Іж јдҪҚ移引ж“ҺжңҖй«ҳеҸҜд»ҘжҸҗеҚҮ15еҖҚBVHйҒӢз®—ж•ҲиғҪпјҢдёҰеғ…дҪҝз”Ё1/20зҡ„иЁҳжҶ¶й«”з©әй–“гҖӮ
в–І ж №ж“ҡNVIDIAе®ҳж–№жҸҗдҫӣзҡ„жЎҲдҫӢпјҢиҝ·дҪ з¶Іж јдҪҚ移引ж“ҺжңҖй«ҳеҸҜд»ҘжҸҗеҚҮ15еҖҚBVHйҒӢз®—ж•ҲиғҪпјҢдёҰеғ…дҪҝз”Ё1/20зҡ„иЁҳжҶ¶й«”з©әй–“гҖӮ
зӮәдәҶиҰҒжҸҗй«ҳе…үз·ҡиҝҪи№Өз№Әең–зҡ„йҖјзңҹзЁӢеәҰпјҢе°ұеҝ…йңҖиҰҒиҝҪеҠ е…үз·ҡзҡ„ж•ёйҮҸиҲҮеҸҚеҪҲж¬Ўж•ёпјҢдёҰжүҝеҸ—йҒӢз®—йңҖжұӮеўһеҠ зҡ„д»Јеғ№пјҢеҸҰеӨ–йҡЁж©ҹи·Ҝеҫ‘иҝҪи№Өжј”з®—жі•иҲҮиӨҮйӣңзҡ„жқҗж–ҷиЎЁйқўд№ҹйғҪжңғеўһеҠ йҒӢз®—иӨҮйӣңеәҰгҖӮйҖҷдәӣзӢҖжіҒжңғйҖ жҲҗ2зЁ®дёҚеҗҢеһӢејҸзҡ„еҲҶжӯ§пјҢеҹ·иЎҢеҲҶжӯ§жҳҜеҗҢдёҖжёІжҹ“еҷЁе…§зҡ„еҹ·иЎҢз·’иҷ•зҗҶдёҚеҗҢзҡ„жёІжҹ“жҲ–зЁӢејҸжҢҮд»ӨпјҢиҖҢиіҮж–ҷеҲҶжӯ§еүҮжҳҜеҹ·иЎҢз·’йңҖиҰҒиҷ•зҗҶйӣЈд»ҘеҗҲдҪөжҲ–жҡ«еӯҳзҡ„иЁҳжҶ¶й«”иіҮж–ҷпјҢйҖҷ2зЁ®еҲҶжӯ§йғҪе°Қж–јж“…й•·иҷ•зҗҶеӨ§йҮҸеҗҢиіӘе·ҘдҪңиІ ијүзҡ„з№Әең–иҷ•зҗҶеҷЁпјҲGPUпјүзӣёз•¶дёҚеҸӢе–„пјҢдёҰжңғжӢ–зҙҜж•ҲиғҪиЎЁзҸҫгҖӮеңЁе…үз·ҡиҝҪи№Өз№Әең–дёӯпјҢеҸҚе°„гҖҒй–“жҺҘз…§жҳҺе’ҢеҚҠйҖҸжҳҺзӯүж•Ҳжһңд№ҹжңғйҖ жҲҗдёҠиҝ°зҡ„еҲҶжӯ§е•ҸйЎҢгҖӮ
Ada Lovelaceз№Әең–жһ¶ж§Ӣе°Һе…Ҙзҡ„жёІжҹ“еҷЁеҹ·иЎҢйҮҚж–°жҺ’еәҸпјҲShader Execution ReorderingпјҢSERпјүиғҪеӨ еҚіжҷӮиӘҝеәҰе·ҘдҪңеҲҶй…ҚпјҢд»ҘйҒ”еҲ°жӣҙзҗҶжғізҡ„еҹ·иЎҢж•ҲзҺҮиҲҮиіҮж–ҷзөҗж§ӢпјҢдёҰзҷјжҸ®жҸҗеҚҮж•ҲиғҪиЎЁзҸҫзҡ„еҠҹж•ҲгҖӮ
з”ұж–јSERжҠҖиЎ“жңғеӨ§йҮҸеҚ з”Ёеҝ«еҸ–иЁҳжҶ¶й«”пјҢеӣ жӯӨAda Lovelaceзі»еҲ—йЎҜзӨәеҚЎеәҰеӨ§е№…жҸҗеҚҮL2еҝ«еҸ–иЁҳжҶ¶й«”зҡ„е®№йҮҸпјҢд»ҘGeForce RTX 3090 TiиҲҮGeForce RTX 4090зӣёжҜ”пјҢеҪјжӯӨзҡ„L2еҝ«еҸ–иЁҳжҶ¶й«”е®№йҮҸз”ұ6MBеӨ§е№…жҸҗеҚҮиҮі72MBгҖӮйӣ–然е…ҲеүҚзҡ„йЎҜзӨәеҚЎжһ¶ж§ӢеңЁзҗҶи«–дёҠд№ҹиғҪж”ҜжҸҙSERжҠҖиЎ“пјҢдҪҶеҸ—еҲ°еҝ«еҸ–иЁҳжҶ¶й«”е®№йҮҸйҷҗеҲ¶пјҢжүҖд»Ҙж•ҲжһңеҸҜиғҪдёҚжңғеӨӘзҗҶжғігҖӮ
ж №ж“ҡNVIDIAйҖІиЎҢзҡ„еҲҶжһҗпјҢSERиғҪеӨ жҸҗеҚҮ2еҖҚе…үз·ҡиҝҪи№Өз№Әең–ж•ҲиғҪпјҢдёҰеңЁгҖҠйӣ»йҰӯеҸӣе®ў2077гҖӢOverdrive Modeи¶…й«ҳз•«иіӘжЁЎејҸдёӢпјҢжҸҗеҚҮж•ҙй«”FPSж•ҲиғҪйҒ”44%пјҢеҸҜиҰӢйҖҷй …еҠҹиғҪзҡ„е°ҚйҒҠжҲІй«”й©—жңүзӣёз•¶еӨ§зҡ„幫еҠ©гҖӮ
з”ұж–јSERе®Ңе…Ёз”ұAPIжүҖжҺ§еҲ¶пјҢжүҖд»ҘйҒҠжҲІй–ӢзҷјиҖ…еҸҜд»ҘйҖҸйҒҺNVAPIиј•й¬Ҷе°Һе…ҘSERеҠҹиғҪпјҲдёҚйҒҺйҖҷд№ҹд»ЈиЎЁзҸҫжңүйҒҠжҲІйңҖиҰҒйҖҸйҒҺжӣҙж–°жүҚиғҪж”ҜжҸҙSERпјүпјҢNVIDIAд№ҹиЎЁзӨәд»–еҖ‘жӯЈеңЁй–ӢзҷјNSightең–еҪўжёІжҹ“еҷЁзҡ„ж–°еҠҹиғҪпјҢд»Ҙз°ЎеҢ–SERзҡ„жңҖдҪіеҢ–пјҢдёҰиҲҮMicrosoftе’Ңе…¶д»–е…¬еҸёеҗҲдҪңпјҢе°ҮSERжҺЁе»ЈзӮәжЁҷжә–з№Әең–APIпјҢд»Ҙи®“SERжӣҙеҠ жҷ®еҸҠгҖӮ
 в–І SERзҡ„еҠҹиғҪзӮәе°ҮеҺҹжң¬ж··дәӮзҡ„жҢҮд»ӨиҲҮиіҮж–ҷпјҢйҮҚж–°жҺ’еәҸзӮәйҒ©еҗҲз№Әең–иҷ•зҗҶеҷЁйҒӢз®—зҡ„еҗҢиіӘиіҮж–ҷгҖӮ
в–І SERзҡ„еҠҹиғҪзӮәе°ҮеҺҹжң¬ж··дәӮзҡ„жҢҮд»ӨиҲҮиіҮж–ҷпјҢйҮҚж–°жҺ’еәҸзӮәйҒ©еҗҲз№Әең–иҷ•зҗҶеҷЁйҒӢз®—зҡ„еҗҢиіӘиіҮж–ҷгҖӮ
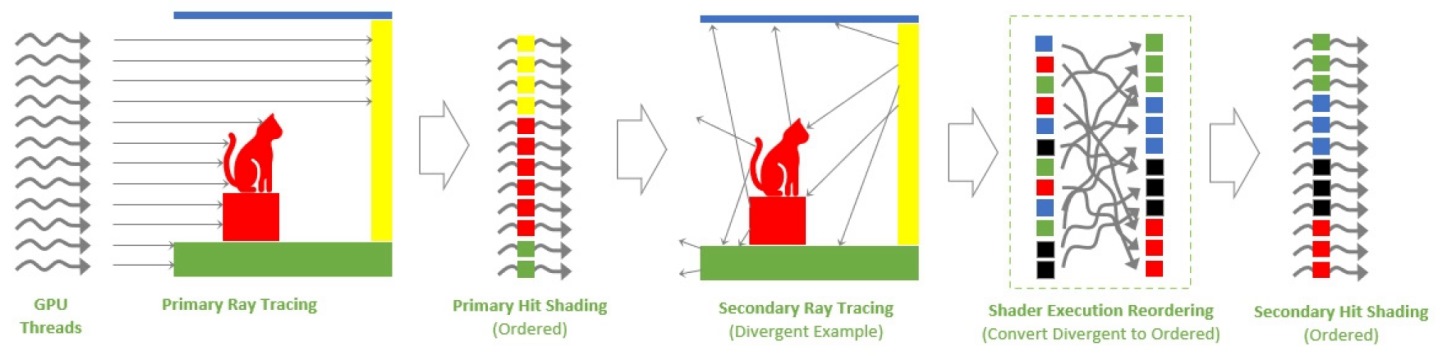 в–І е…үз·ҡиҝҪи№Өз№Әең–зҡ„еҸҚе°„гҖҒй–“жҺҘз…§жҳҺгҖҒеҚҠйҖҸжҳҺеҫҖеҫҖжңғи®“иіҮж–ҷзөҗж§Ӣи¶Ёж–јзҷјж•ЈпјҢSERиғҪеӨ йҮҚж–°жҺ’еәҸдёҰжҸҗеҚҮз№Әең–иҷ•зҗҶеҷЁзҡ„ж•ҲиғҪиЎЁзҸҫгҖӮ
в–І е…үз·ҡиҝҪи№Өз№Әең–зҡ„еҸҚе°„гҖҒй–“жҺҘз…§жҳҺгҖҒеҚҠйҖҸжҳҺеҫҖеҫҖжңғи®“иіҮж–ҷзөҗж§Ӣи¶Ёж–јзҷјж•ЈпјҢSERиғҪеӨ йҮҚж–°жҺ’еәҸдёҰжҸҗеҚҮз№Әең–иҷ•зҗҶеҷЁзҡ„ж•ҲиғҪиЎЁзҸҫгҖӮ
Ada LovelaceйҷӨдәҶеӨ§е№…зҝ»ж–°е…үз·ҡиҝҪи№Өз№Әең–зҡ„йҒӢз®—жһ¶ж§ӢеӨ–пјҢеңЁйҖҸйҒҺAIйҖІиЎҢз•«йқўеҚҮй »зҡ„DLSS 3жҠҖиЎ“д№ҹжңүиЁұеӨҡдә®й»һпјҢзӯҶиҖ…е°ҮеңЁдёӢдёҖзҜҮж–Үз« дёӯйҖІиЎҢд»Ӣзҙ№иҲҮеҜҰйҡӣжё¬и©ҰгҖӮ
зі»еҲ—ж–Үз« пјҡ
NVIDIA GeForce RTX 4090еүөе§ӢзүҲй–Ӣз®ұжҗ¶е…ҲзңӢпјҢж–°дё–д»ЈеҚЎзҺӢеҚіе°ҮйҷҚиҮЁпјҒ
GeForce RTX 4090ж•ҲиғҪеҜҰжё¬пјҢж–°дё–д»ЈеҚЎзҺӢжҡўзҺ©4Kе…үз·ҡиҝҪи№Ө
NVIDIA Ada Lovelaceжһ¶ж§Ӣи§ЈжһҗпјҲдёҖпјүпјҡе…үз·ҡиҝҪи№Өж•ҲиғҪеӨ§зҲҶзҷјпјҲжң¬ж–Үпјү
NVIDIA Ada Lovelaceжһ¶ж§Ӣи§ЈжһҗпјҲдәҢпјүпјҡеҜҰжё¬DLSS 3и®“йҒҠжҲІж•ҲиғҪеҶҚж¬Ўзҝ»еҖҚпјҲиЈҪдҪңдёӯпјү
В
еҠ е…ҘTе®ўйӮҰFacebookзІүзөІеңҳ еӣәе®ҡй“ҫжҺҘ 'NVIDIA Ada Lovelaceжһ¶ж§Ӣи§ЈжһҗпјҲдёҖпјүпјҡе…үз·ҡиҝҪи№Өж•ҲиғҪеӨ§зҲҶзҷј' жҸҗдәӨ: October 12, 2022, 5:00pm CST